
Evaluación integral del rendimiento de Vera: una valoración multibenchmark a través de dominios del conocimiento médico
Resumen
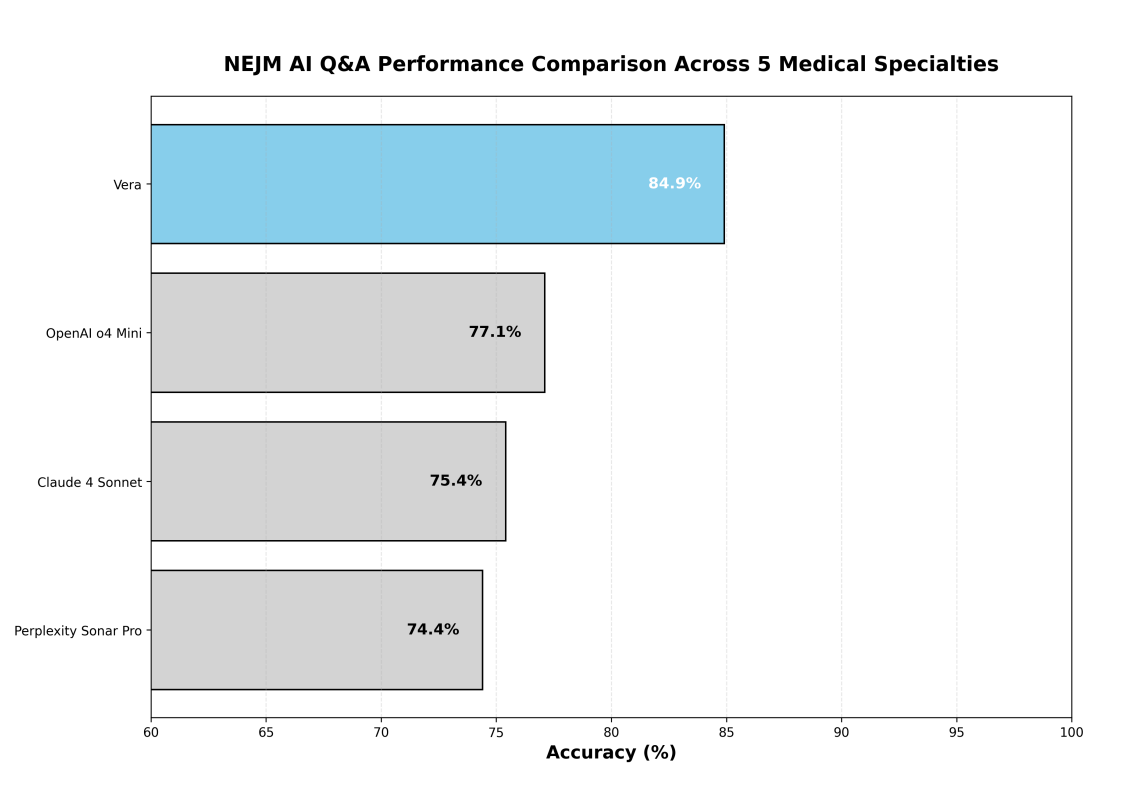
Presentamos una evaluación integral de Vera, un sistema avanzado de apoyo a la decisión clínica diseñado para dotar a los profesionales sanitarios de orientación médica instantánea y basada en la evidencia. Vera aprovecha sofisticados agentes de IA y tecnología de Generación Aumentada por Recuperación, sintetizando el conocimiento de más de 60 millones de publicaciones médicas revisadas por pares para ofrecer respuestas fiables y contextualmente apropiadas. Esta valoración multibenchmark evalúa el rendimiento de Vera en tres dominios distintos del conocimiento médico: el Examen de Licencia Médica de los Estados Unidos (USMLE), el conjunto de datos de preguntas y respuestas de IA del New England Journal of Medicine (NEJM-AI) y el benchmark MedXpertQA. En USMLE, Vera logró una precisión global excepcional del 97.5 %, con precisiones específicas por paso del 97.9 % (Step 1), 98.2 % (Step 2 CK) y 96.7 % (Step 3). En el benchmark NEJM-AI, compuesto por 655 preguntas de cinco especialidades médicas, Vera demostró un rendimiento superior con una precisión del 84.9 %, superando a modelos de IA líderes como OpenAI o4 Mini (77.1 %), Claude 4 Sonnet (75.4 %) y Perplexity Sonar Pro (74.4 %). En el benchmark MedXpertQA, compuesto por 500 preguntas a través de múltiples sistemas corporales y tareas médicas, Vera logró una precisión del 62.2 %, demostrando un sólido rendimiento en escenarios especializados de razonamiento clínico. Vera logró la mayor precisión en cuatro de las cinco especialidades médicas de NEJM-AI, con un rendimiento particularmente sólido en Pediatría (93.9 %) y Medicina interna (87.3 %). Estos resultados a través de diversos marcos de evaluación subrayan la robusta representación del conocimiento médico y las capacidades de razonamiento de Vera, posicionándola como una solución líder para el apoyo a la decisión clínica.
Introducción
Los profesionales sanitarios de diversos entornos clínicos requieren acceso rápido a un conocimiento médico preciso y basado en la evidencia para respaldar una atención óptima al paciente. El crecimiento exponencial de la literatura médica plantea desafíos sin precedentes para la recuperación y síntesis oportuna del conocimiento. Vera aborda esta necesidad crítica combinando sofisticados agentes de IA con tecnología avanzada de Generación Aumentada por Recuperación, ofreciendo orientación clínica fiable aproximadamente diez veces más rápido que los métodos convencionales.
La evaluación de los sistemas de IA médica requiere una valoración rigurosa a través de múltiples dominios para garantizar un rendimiento robusto en escenarios clínicos del mundo real. Si bien los benchmarks individuales aportan información valiosa, una evaluación integral a través de diversos marcos de conocimiento ofrece una imagen más completa de las capacidades y limitaciones del sistema. Este estudio presenta una evaluación multibenchmark de Vera utilizando tres marcos de valoración complementarios: el Examen de Licencia Médica de los Estados Unidos (USMLE), el conjunto de datos de preguntas y respuestas de IA del New England Journal of Medicine (NEJM-AI) y el benchmark MedXpertQA.
USMLE proporciona una medida estandarizada del conocimiento médico fundamental a través de los dominios de ciencias básicas, conocimiento clínico y manejo del paciente. Sin embargo, refleja principalmente contenido educativo previo a la licencia y puede no captar plenamente la complejidad de la toma de decisiones clínicas contemporánea. Para abordar esta limitación, complementamos nuestra evaluación con el benchmark NEJM-AI, que presenta 655 preguntas de orientación clínica a través de cinco grandes especialidades médicas, aportando información sobre el rendimiento en escenarios más relevantes para la práctica. Además, evaluamos Vera en el benchmark MedXpertQA, compuesto por 500 preguntas que valoran el razonamiento clínico a través de diversos sistemas corporales, tareas médicas y tipos de preguntas, proporcionando información adicional sobre dominios especializados del conocimiento clínico.
Nuestro análisis integral a través de estos distintos marcos de evaluación revela las fortalezas y características de rendimiento de Vera, demostrando una promesa sustancial para transformar el apoyo a la decisión clínica, mejorar la eficiencia de los profesionales y, en última instancia, mejorar la calidad de la atención al paciente.
Resultados
Resumen del rendimiento multibenchmark
Vera demostró un rendimiento excepcional a través de los tres marcos de evaluación, logrando un 97.5% en USMLE, un 84.9% en el benchmark NEJM-AI y un 62.2% en el benchmark MedXpertQA. La Tabla 1 resume el rendimiento de Vera en todas las valoraciones.
| Benchmark | Precisión |
|---|---|
| USMLE (Global) | 97.5 % |
| Step 1 | 97.9 % |
| Step 2 CK | 98.2 % |
| Step 3 | 96.7 % |
| NEJM-AI (Global) | 84.9 % |
| MedXpertQA (Global) | 62.2 % |
Análisis del rendimiento en USMLE
En la valoración USMLE, Vera logró una precisión casi perfecta en todos los niveles del examen, demostrando un conocimiento médico fundamental robusto. La variación mínima entre pasos (rango: 96.7–98.2 %) indica que la representación del conocimiento de Vera escala eficazmente desde conceptos de ciencias básicas hasta escenarios clínicos complejos que requieren decisiones de manejo del paciente.
Análisis competitivo en USMLE
El rendimiento de Vera establece una clara superioridad sobre otros sistemas de IA médica en la valoración estandarizada del conocimiento médico. La Figura 1 demuestra la ventaja competitiva de Vera en el panorama de la IA médica.
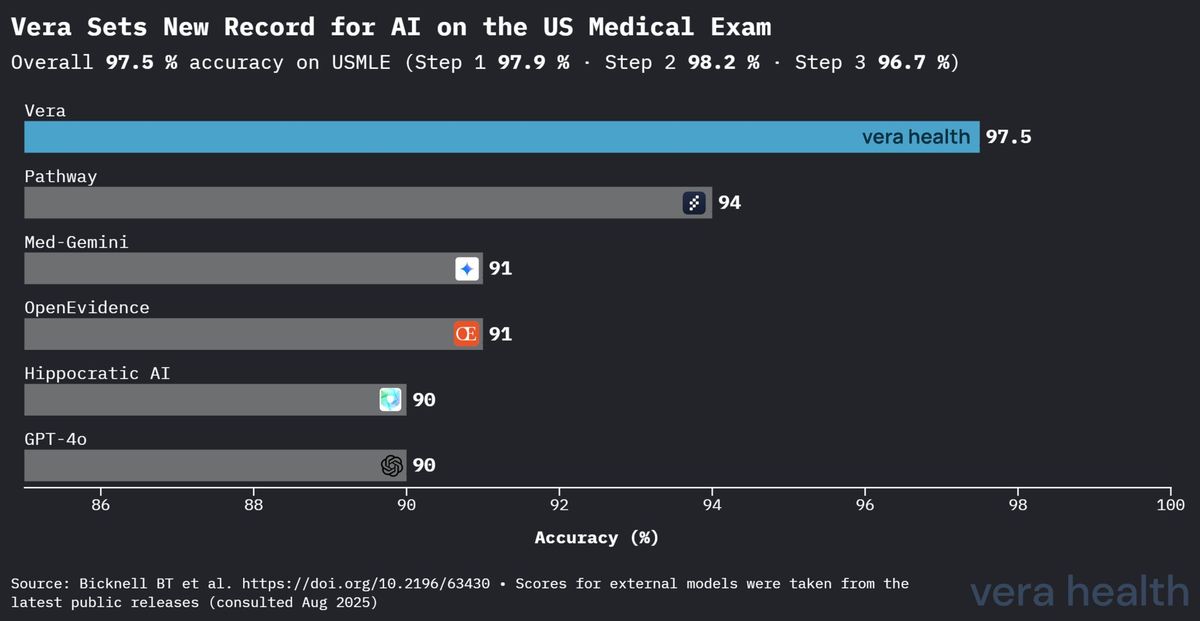
Este análisis competitivo revela varias conclusiones clave: (1) la ventaja de 3.5 puntos porcentuales de Vera sobre el segundo modelo con mejor rendimiento representa una mejora sustancial en la valoración del conocimiento médico; (2) la brecha de rendimiento se amplía significativamente en comparación con los modelos de propósito general, lo que pone de relieve el valor de la optimización específica para la medicina; y (3) la superioridad de Vera abarca tanto los sistemas de IA médica especializados como los principales modelos de lenguaje de propósito general.
Resultados del benchmark competitivo NEJM-AI
En el benchmark NEJM-AI, Vera logró la mayor precisión global entre todos los modelos evaluados, superando a los sistemas de IA líderes por márgenes sustanciales. La Figura 2 demuestra la superioridad competitiva de Vera.
Análisis del rendimiento específico por especialidad
El rendimiento de Vera varió entre las especialidades médicas, con resultados consistentemente sólidos en la mayoría de los dominios. La Tabla 2 presenta las precisiones detalladas específicas por especialidad.
| Especialidad médica | Preguntas | Precisión de Vera |
|---|---|---|
| Pediatría | 99 | 93.9 % |
| Psiquiatría | 150 | 88.7 % |
| Medicina interna | 126 | 87.3 % |
| Cirugía general | 141 | 83.0 % |
| Ginecología y obstetricia | 139 | 74.1 % |
La Figura 3 ofrece una comparación detallada del rendimiento de Vera frente a los modelos competidores en las cinco especialidades médicas.
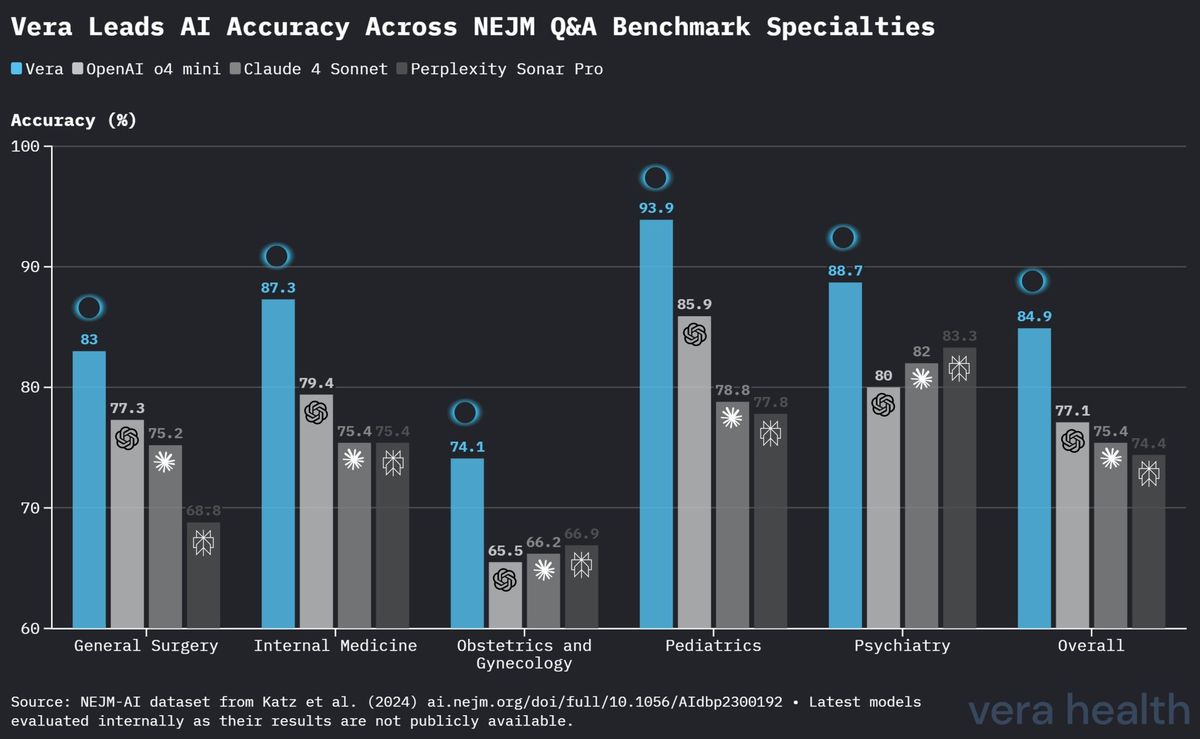
Vera logró la mayor precisión en cuatro de las cinco especialidades: - Pediatría: Rendimiento líder con una precisión del 93.9 % - Medicina interna: Rendimiento sólido con una precisión del 87.3 % - Cirugía general: Ventaja competitiva con una precisión del 83.0 % - Ginecología y obstetricia: Ventaja modesta con una precisión del 74.1 % - Psiquiatría: Rendimiento sólido con una precisión del 88.7 %
Análisis del rendimiento en MedXpertQA
En el benchmark MedXpertQA, Vera logró una precisión del 62.2 % a través de 500 preguntas médicas diversas, demostrando un rendimiento competente en escenarios especializados de razonamiento clínico. La Tabla 3 presenta los desgloses detallados del rendimiento a través de diferentes categorías.
| Categoría | Preguntas | Precisión de Vera |
|---|---|---|
| Por sistema corporal | ||
| Tegumentario | 16 | 81.2 % |
| Esquelético | 81 | 72.8 % |
| Muscular | 36 | 72.2 % |
| Reproductor | 31 | 71.0 % |
| Digestivo | 60 | 63.3 % |
| Endocrino | 37 | 62.2 % |
| Linfático | 22 | 59.1 % |
| Nervioso | 72 | 56.9 % |
| Respiratorio | 32 | 56.2 % |
| Urinario | 18 | 55.6 % |
| Cardiovascular | 68 | 51.5 % |
| Otro/N.D. | 27 | 48.1 % |
| Por tarea médica | ||
| Ciencias básicas | 139 | 66.9 % |
| Tratamiento | 157 | 61.8 % |
| Diagnóstico | 204 | 59.3 % |
| Por tipo de pregunta | ||
| Comprensión | 115 | 66.1 % |
| Razonamiento | 385 | 61.0 % |
Los resultados de MedXpertQA revelan varios patrones notables en el rendimiento de Vera: - Variación por sistema corporal: El rendimiento osciló entre el 81.2 % (Tegumentario) y el 48.1 % (Otro/N.D.), con el rendimiento más sólido en sistemas anatómicamente discretos - Rendimiento por tarea médica: Las preguntas de Ciencias básicas (66.9 %) superaron a las aplicaciones clínicas, lo que sugiere un rendimiento más sólido en el conocimiento fundamental - Análisis por tipo de pregunta: Las preguntas de Comprensión (66.1 %) mostraron un rendimiento superior en comparación con las preguntas de Razonamiento (61.0 %), lo que indica capacidades eficaces de recuperación del conocimiento
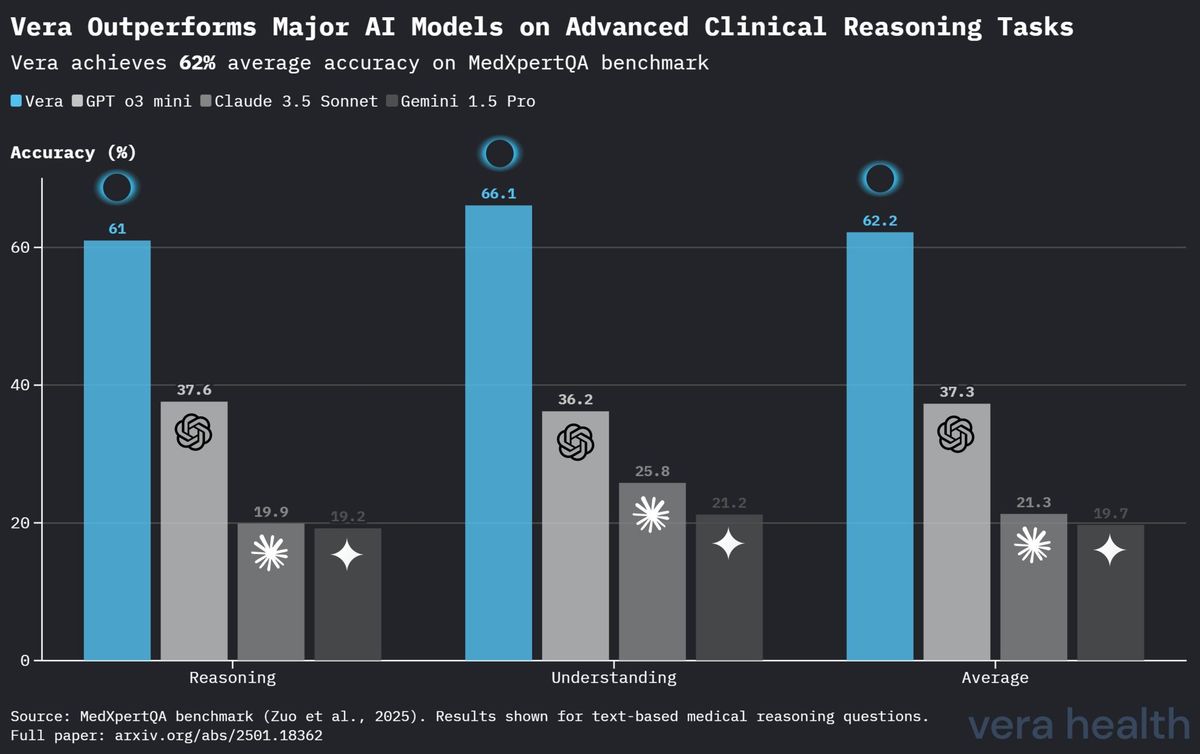
Rendimiento comparativo de los modelos en MedXpertQA
La Tabla 4 presenta un análisis comparativo del rendimiento de Vera frente a otros modelos de IA líderes en el benchmark MedXpertQA, destacando el posicionamiento competitivo de Vera en tareas especializadas de razonamiento clínico.
| Modelo | Razonamiento | Comprensión | Promedio |
|---|---|---|---|
| Vera | 61.0 % | 66.1 % | 62.2 % |
| OpenAI o3 Mini | 37.6 % | 36.2 % | 37.3 % |
| Claude 3.5 Sonnet | 19.9 % | 25.8 % | 21.3 % |
| Gemini 1.5 Pro | 19.2 % | 21.2 % | 19.7 % |
Métodos
Marco de evaluación
Realizamos una evaluación multibenchmark integral utilizando tres marcos distintos de valoración del conocimiento médico: el Examen de Licencia Médica de los Estados Unidos (USMLE), el conjunto de datos de preguntas y respuestas de IA del New England Journal of Medicine (NEJM-AI) y el benchmark MedXpertQA. Este enfoque de tres benchmarks permite valorar el conocimiento médico fundamental, las capacidades contemporáneas de razonamiento clínico y la experiencia especializada en dominios clínicos.
Valoración USMLE
Tomamos muestras de preguntas de opción múltiple de recursos oficiales de preparación para el USMLE que abarcan los tres pasos del examen: Step 1 (ciencias básicas), Step 2 Clinical Knowledge (conocimiento y habilidades clínicas) y Step 3 (manejo del paciente). Cada pregunta incluía una viñeta clínica, varias opciones de respuesta, una clave de respuesta de referencia y una clasificación por especialidad. Las preguntas se presentaron a Vera exactamente como estaban redactadas, utilizando el prompt del sistema de producción sin optimización específica para el benchmark.
Evaluación del benchmark NEJM-AI
El conjunto de datos NEJM-AI (Katz et al., 2024) consta de 655 preguntas de opción múltiple de orientación clínica distribuidas entre cinco grandes especialidades médicas: Cirugía general (141 preguntas), Medicina interna (126 preguntas), Ginecología y obstetricia (139 preguntas), Pediatría (99 preguntas) y Psiquiatría (150 preguntas). Este benchmark fue diseñado para valorar el conocimiento clínico contemporáneo y las capacidades de razonamiento relevantes para los médicos en ejercicio. El estudio original informó que GPT-4 alcanzó una precisión del 74.7% en este benchmark.
Evaluación del benchmark MedXpertQA
El conjunto de datos MedXpertQA (Zuo et al., 2025) es un benchmark altamente exigente diseñado para evaluar el razonamiento y la comprensión médica a nivel de experto. Compuesto por 4,460 preguntas que abarcan 17 especialidades médicas y 11 sistemas corporales, MedXpertQA representa una de las valoraciones de razonamiento médico más completas y difíciles disponibles. El benchmark incluye dos subconjuntos: MedXpertQA Text para la evaluación médica basada en texto y MedXpertQA MM para la evaluación médica multimodal.
Para nuestra evaluación, utilizamos una muestra representativa de 500 preguntas del subconjunto MedXpertQA Text, manteniendo los rigurosos estándares del benchmark a la vez que permitíamos una valoración eficiente. Las preguntas se categorizan por sistema corporal (12 categorías), tarea médica (Ciencias básicas, Diagnóstico, Tratamiento) y tipo de pregunta (Comprensión, Razonamiento). Este benchmark valora el conocimiento clínico especializado y las capacidades de razonamiento a través de un amplio espectro de escenarios médicos, desde la ciencia fundamental hasta aplicaciones clínicas complejas, lo que lo hace particularmente valioso para evaluar sistemas avanzados de IA médica.
Protocolo experimental
Para los tres benchmarks, mantuvimos protocolos de evaluación consistentes: - Todas las preguntas se presentaron a Vera utilizando el prompt del sistema de producción estándar sin ninguna ingeniería de prompts específica para el benchmark - El modo opcional Deep Dive se desactivó para reflejar el modo de respuesta rápida preferido por los clínicos en entornos del mundo real - Cada pregunta se procesó de forma independiente, sin contexto previo ni optimización específica para la pregunta - La precisión de las respuestas se determinó mediante coincidencia exacta con las respuestas de referencia proporcionadas
Análisis competitivo
Para el benchmark NEJM-AI, comparamos el rendimiento de Vera con tres sistemas de IA médica líderes: OpenAI o4 Mini, Claude 4 Sonnet y Perplexity Sonar Pro. Dado que los últimos modelos de OpenAI, Anthropic y Perplexity no están disponibles públicamente, realizamos evaluaciones internas utilizando nuestras propias implementaciones. Todos los modelos se evaluaron sobre el mismo conjunto de 655 preguntas utilizando sus respectivas configuraciones óptimas. Si bien el estudio original de NEJM-AI informó que GPT-4 alcanzó una precisión del 74.7%, lo excluimos de nuestro análisis comparativo, ya que OpenAI o4 Mini demostró un rendimiento superior.
Análisis estadístico
Calculamos las tasas de precisión global, las métricas de rendimiento específicas por especialidad y las clasificaciones comparativas. Las variaciones de rendimiento entre especialidades se analizaron para identificar fortalezas específicas de dominio y áreas de mejora.
Discusión
Complementariedad de los benchmarks e implicaciones clínicas
La evaluación de tres benchmarks revela perspectivas distintas pero complementarias sobre las capacidades de Vera. El excepcional rendimiento en USMLE (precisión del 97.5 %) demuestra el dominio del conocimiento médico fundamental a través de los dominios de ciencias básicas, conocimiento clínico y manejo del paciente. El sólido rendimiento en NEJM-AI (precisión del 84.9 %), con una superioridad competitiva sobre los modelos de IA líderes, indica capacidades robustas en escenarios contemporáneos de razonamiento clínico. El rendimiento en MedXpertQA (precisión del 62.2 %) aporta información sobre la experiencia especializada en dominios clínicos y el razonamiento a través de diversos sistemas corporales y tareas médicas.
El diferencial de rendimiento entre benchmarks (97.5 % frente a 84.9 % frente a 62.2 %) probablemente refleja la naturaleza y complejidad distintas de estas valoraciones. Las preguntas de USMLE evalúan principalmente el conocimiento médico estandarizado con claves de respuesta establecidas, mientras que las preguntas de NEJM-AI presentan escenarios clínicos más matizados que pueden admitir múltiples enfoques razonables. MedXpertQA representa la valoración más exigente, con escenarios complejos de razonamiento clínico que requieren la integración de conocimiento especializado a través de múltiples dominios, lo que la convierte en una prueba rigurosa de competencia clínica avanzada.
Posicionamiento competitivo
El rendimiento de Vera en el benchmark NEJM-AI establece claras ventajas competitivas sobre los sistemas de IA médica actuales. La ventaja sustancial sobre los modelos competidores representa una mejora significativa en un campo altamente competitivo. Más significativamente, la superioridad consistente de Vera en cuatro de las cinco especialidades médicas demuestra un conocimiento clínico de base amplia en lugar de una optimización específica de dominio.
Los resultados específicos por especialidad revelan información importante: - Pediatría: La excepcional precisión del 93.9 % sugiere un rendimiento sólido en un dominio que requiere consideraciones especializadas del desarrollo y específicas de la edad - Medicina interna: La precisión del 87.3 % demuestra competencia en el razonamiento de base amplia que requiere esta especialidad fundamental - Ginecología y obstetricia: La precisión comparativamente más baja del 74.1 %, aunque sigue liderando a los competidores, indica posibles áreas para una mejora específica
Generalización y robustez del sistema
El rendimiento elevado y consistente a través de diversos marcos de evaluación sugiere que los mecanismos de representación del conocimiento y razonamiento de Vera se generalizan eficazmente a través de diferentes formatos de preguntas, niveles de dificultad y contextos clínicos. Esta robustez es particularmente importante para el despliegue clínico, donde el sistema debe manejar diversos tipos de consultas y escenarios clínicos.
Limitaciones y consideraciones
A pesar de estos resultados alentadores, varias limitaciones merecen consideración: 1. Alcance del benchmark: Ambas evaluaciones se basan en formatos de opción múltiple que pueden no captar plenamente la complejidad de la toma de decisiones clínicas del mundo real, que a menudo implica incertidumbre, información incompleta y presentaciones de pacientes multifacéticas. 2. Conocimiento clínico frente a académico: Un rendimiento elevado en benchmarks académicos no garantiza una eficacia clínica óptima en el mundo real. El diseño de Vera prioriza las guías clínicas contemporáneas y la práctica basada en la evidencia, lo que ocasionalmente puede divergir de las claves de respuesta de exámenes históricos. 3. Variación por especialidad: La variación de rendimiento observada entre las especialidades médicas sugiere que ciertos dominios pueden beneficiarse de una mejora específica, particularmente Ginecología y obstetricia, donde el rendimiento, aunque competitivo, mostró el mayor margen de mejora. 4. Consideraciones temporales: El conocimiento médico evoluciona rápidamente con nuevos hallazgos de investigación y actualizaciones de las guías. La evaluación continua y la actualización del modelo serán esenciales para mantener el rendimiento a lo largo del tiempo. 5. Metodología de evaluación: Ambos benchmarks se basan en claves de respuesta predeterminadas que pueden no reflejar siempre el espectro completo de respuestas clínicamente aceptables, lo que potencialmente subestima el rendimiento del sistema en escenarios ambiguos.
Conclusiones
Esta evaluación multibenchmark integral demuestra las capacidades excepcionales de Vera a través de diversos dominios del conocimiento médico. El sistema logró una precisión casi perfecta en USMLE (97.5 %), estableció una superioridad competitiva en el benchmark NEJM-AI (84.9 %) y demostró un rendimiento competente en el exigente benchmark MedXpertQA (62.2 %). En NEJM-AI, Vera superó a modelos de IA líderes como OpenAI o4 Mini, Claude 4 Sonnet y Perplexity Sonar Pro.
Los hallazgos clave incluyen: - Amplia competencia médica: Rendimiento elevado y consistente a través de los dominios del conocimiento fundamental (USMLE), clínico contemporáneo (NEJM-AI) y de razonamiento especializado (MedXpertQA) - Ventaja competitiva: Clara superioridad sobre los sistemas de IA médica actuales en la evaluación directa - Robustez por especialidad: Rendimiento líder en cuatro de las cinco especialidades médicas de NEJM-AI, con resultados particularmente sólidos en Pediatría y Medicina interna - Experiencia específica de dominio: Rendimiento sólido a través de diversos sistemas corporales en MedXpertQA, con una fortaleza particular en sistemas anatómicamente discretos (Tegumentario: 81.2 %, Esquelético: 72.8 %) - Generalización del conocimiento: Rendimiento eficaz a través de diversos formatos de preguntas, niveles de dificultad y contextos clínicos
Estos resultados posicionan a Vera como una solución líder para el apoyo a la decisión clínica, con capacidades demostradas que superan los benchmarks actuales para los sistemas de IA médica. El enfoque de tres benchmarks proporciona evidencia robusta del rendimiento del sistema a través de escenarios académicos, clínicamente relevantes y de razonamiento especializado, respaldando su despliegue en aplicaciones de educación médica, formación clínica y apoyo a la decisión en el punto de atención.
Disponibilidad de los datos
Los conjuntos de datos de evaluación y los resultados detallados están disponibles previa solicitud (enterprise@vera-health.ai) y se proporcionarán sujetos a los acuerdos estándar de uso de datos y a las salvaguardas de privacidad.
Referencias
[1] Katz, U., Cohen, E., Shachar, E., Somer, J., Fink, A., Morse, E., Shreiber, B., & Wolf, I. (2024). GPT versus Resident Physicians — A Benchmark Based on Official Board Scores. NEJM AI, 1(5), AIdbp2300192. https://doi.org/10.1056/AIdbp2300192 [2] Zuo, Y., Qu, S., Li, Y., Chen, Z., Zhu, X., Hua, E., Zhang, K., Ding, N., & Zhou, B. (2025). MedXpertQA: Benchmarking expert-level medical reasoning and understanding. arXiv preprint arXiv:2501.18362. [3] Bicknell, B. T., Butler, D., Whalen, S., Ricks, J., Dixon, C. J., Clark, A. B., Spaedy, O., Skelton, A., Edupuganti, N., Dzubinski, L., Tate, H., Dyess, G., Lindeman, B., & Lehmann, L. S. (2024). ChatGPT-4 Omni Performance in USMLE Disciplines and Clinical Skills: Comparative Analysis. JMIR medical education, 10, e63430. https://doi.org/10.2196/63430
Sobre Vera Health
Vera es una herramienta de apoyo a la decisión clínica (CDS) impulsada por IA, diseñada para ayudar a los profesionales sanitarios a tomar decisiones basadas en la evidencia de forma más eficiente. Vera aprovecha sofisticados agentes de IA y tecnología de Generación Aumentada por Recuperación, sintetizando el conocimiento de más de 60 millones de publicaciones médicas revisadas por pares para ofrecer respuestas fiables y contextualmente apropiadas en el punto de atención. Con su tecnología de IA de vanguardia, Vera permite a los clínicos mejorar los resultados de los pacientes y agilizar los procesos de toma de decisiones.


