
Évaluation complète des performances de Vera : une analyse multi-référentiels à travers les domaines de connaissances médicales
Résumé
Nous présentons une évaluation complète de Vera, un système avancé d’aide à la décision clinique conçu pour offrir aux professionnels de santé une orientation médicale instantanée et fondée sur les preuves. Vera s’appuie sur des agents d’IA sophistiqués et sur la technologie de génération augmentée par récupération (Retrieval-Augmented Generation), en synthétisant les connaissances issues de plus de 60 millions de publications médicales évaluées par les pairs afin de fournir des réponses fiables et adaptées au contexte. Cette évaluation multi-référentiels analyse les performances de Vera à travers trois domaines distincts de connaissances médicales : l’examen de licence médicale des États-Unis (USMLE), le jeu de données de questions-réponses du New England Journal of Medicine consacré à l’IA (NEJM-AI) et le référentiel MedXpertQA. Sur l’USMLE, Vera a atteint une exactitude globale exceptionnelle de 97.5 %, avec des exactitudes spécifiques par étape de 97.9 % (Step 1), 98.2 % (Step 2 CK) et 96.7 % (Step 3). Sur le référentiel NEJM-AI comprenant 655 questions réparties sur cinq spécialités médicales, Vera a démontré des performances supérieures avec une exactitude de 84.9 %, surpassant les principaux modèles d’IA, notamment OpenAI o4 Mini (77.1 %), Claude 4 Sonnet (75.4 %) et Perplexity Sonar Pro (74.4 %). Sur le référentiel MedXpertQA comprenant 500 questions réparties sur plusieurs systèmes corporels et tâches médicales, Vera a atteint une exactitude de 62.2 %, démontrant de solides performances dans des scénarios de raisonnement clinique spécialisé. Vera a obtenu l’exactitude la plus élevée dans quatre des cinq spécialités médicales du NEJM-AI, avec des performances particulièrement solides en Pédiatrie (93.9 %) et en Médecine interne (87.3 %). Ces résultats, obtenus à travers divers cadres d’évaluation, soulignent la solidité de la représentation des connaissances médicales et des capacités de raisonnement de Vera, la positionnant comme une solution de premier plan pour l’aide à la décision clinique.
Introduction
Les professionnels de santé exerçant dans des environnements cliniques variés ont besoin d’un accès rapide à des connaissances médicales précises et fondées sur les preuves afin de soutenir des soins optimaux aux patients. La croissance exponentielle de la littérature médicale pose des défis sans précédent pour une récupération et une synthèse des connaissances en temps voulu. Vera répond à ce besoin essentiel en combinant des agents d’IA sophistiqués avec une technologie avancée de génération augmentée par récupération (Retrieval-Augmented Generation), offrant une orientation clinique fiable environ dix fois plus rapidement que les méthodes conventionnelles.
L’évaluation des systèmes d’IA médicale exige une analyse rigoureuse à travers de multiples domaines afin de garantir des performances solides dans des scénarios cliniques du monde réel. Si les référentiels individuels offrent des éclairages précieux, une évaluation complète à travers des cadres de connaissances variés permet d’obtenir une image plus complète des capacités et des limites du système. Cette étude présente une évaluation multi-référentiels de Vera à l’aide de trois cadres d’évaluation complémentaires : l’examen de licence médicale des États-Unis (USMLE), le jeu de données de questions-réponses du New England Journal of Medicine consacré à l’IA (NEJM-AI) et le référentiel MedXpertQA.
L’USMLE fournit une mesure standardisée des connaissances médicales fondamentales à travers les domaines des sciences fondamentales, des connaissances cliniques et de la prise en charge des patients. Toutefois, il reflète principalement le contenu pédagogique antérieur à l’obtention de la licence et peut ne pas saisir pleinement la complexité de la prise de décision clinique contemporaine. Pour pallier cette limite, nous complétons notre évaluation par le référentiel NEJM-AI, qui présente 655 questions à orientation clinique réparties sur cinq grandes spécialités médicales, offrant des éclairages sur les performances dans des scénarios plus proches de la pratique. En outre, nous évaluons Vera sur le référentiel MedXpertQA, comprenant 500 questions qui évaluent le raisonnement clinique à travers divers systèmes corporels, tâches médicales et types de questions, fournissant des éclairages supplémentaires sur les domaines de connaissances cliniques spécialisées.
Notre analyse complète à travers ces différents cadres d’évaluation révèle les points forts et les caractéristiques de performance de Vera, démontrant un potentiel substantiel pour transformer l’aide à la décision clinique, améliorer l’efficacité des praticiens et, en définitive, améliorer la qualité des soins aux patients.
Résultats
Aperçu des performances multi-référentiels
Vera a démontré des performances exceptionnelles à travers les trois cadres d’évaluation, atteignant 97.5 % sur l’USMLE, 84.9 % sur le référentiel NEJM-AI et 62.2 % sur le référentiel MedXpertQA. Le Tableau 1 résume les performances de Vera à travers l’ensemble des évaluations.
| Référentiel | Exactitude |
|---|---|
| USMLE (global) | 97.5 % |
| Step 1 | 97.9 % |
| Step 2 CK | 98.2 % |
| Step 3 | 96.7 % |
| NEJM-AI (global) | 84.9 % |
| MedXpertQA (global) | 62.2 % |
Analyse des performances sur l’USMLE
Sur l’évaluation USMLE, Vera a atteint une exactitude quasi parfaite à tous les niveaux de l’examen, démontrant de solides connaissances médicales fondamentales. La variation minime entre les étapes (plage : 96,7 à 98.2 %) indique que la représentation des connaissances de Vera s’adapte efficacement, depuis les concepts de sciences fondamentales jusqu’aux scénarios cliniques complexes nécessitant des décisions de prise en charge des patients.
Analyse concurrentielle sur l’USMLE
Les performances de Vera établissent une supériorité nette sur les autres systèmes d’IA médicale dans l’évaluation standardisée des connaissances médicales. La Figure 1 illustre l’avantage concurrentiel de Vera à travers le paysage de l’IA médicale.
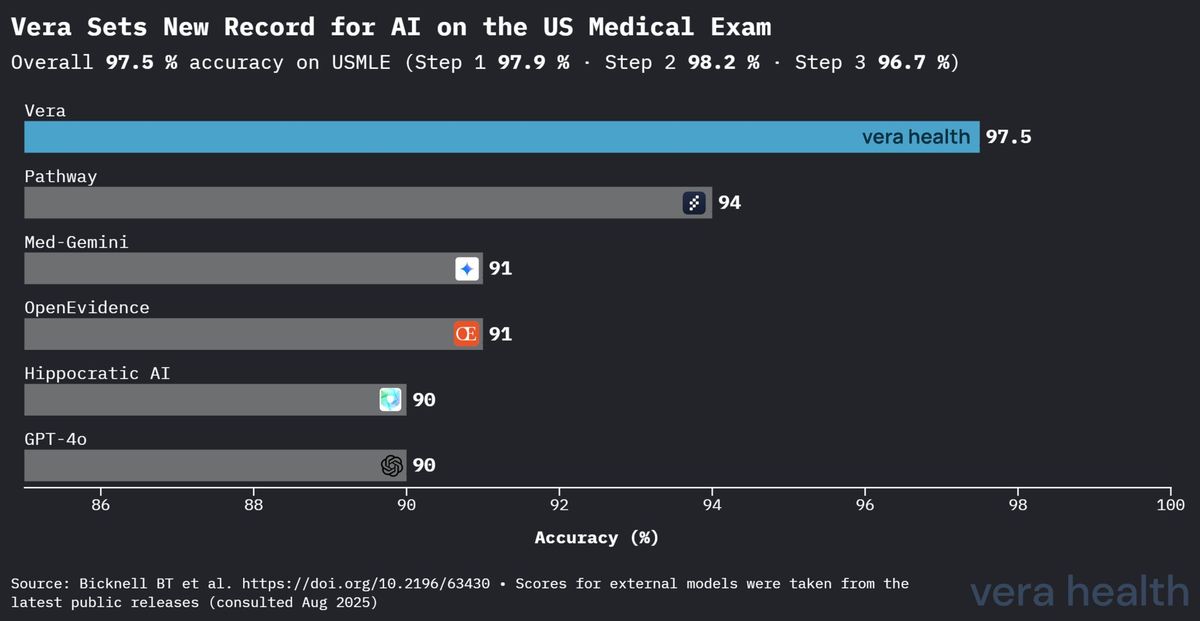
Cette analyse concurrentielle révèle plusieurs éclairages clés : (1) l’avance de 3,5 points de pourcentage de Vera sur le deuxième modèle le plus performant représente une amélioration substantielle dans l’évaluation des connaissances médicales ; (2) l’écart de performance se creuse significativement par rapport aux modèles à usage général, soulignant la valeur d’une optimisation propre au domaine médical ; et (3) la supériorité de Vera s’étend à la fois aux systèmes d’IA médicale spécialisés et aux principaux modèles de langage à usage général.
Résultats du référentiel concurrentiel NEJM-AI
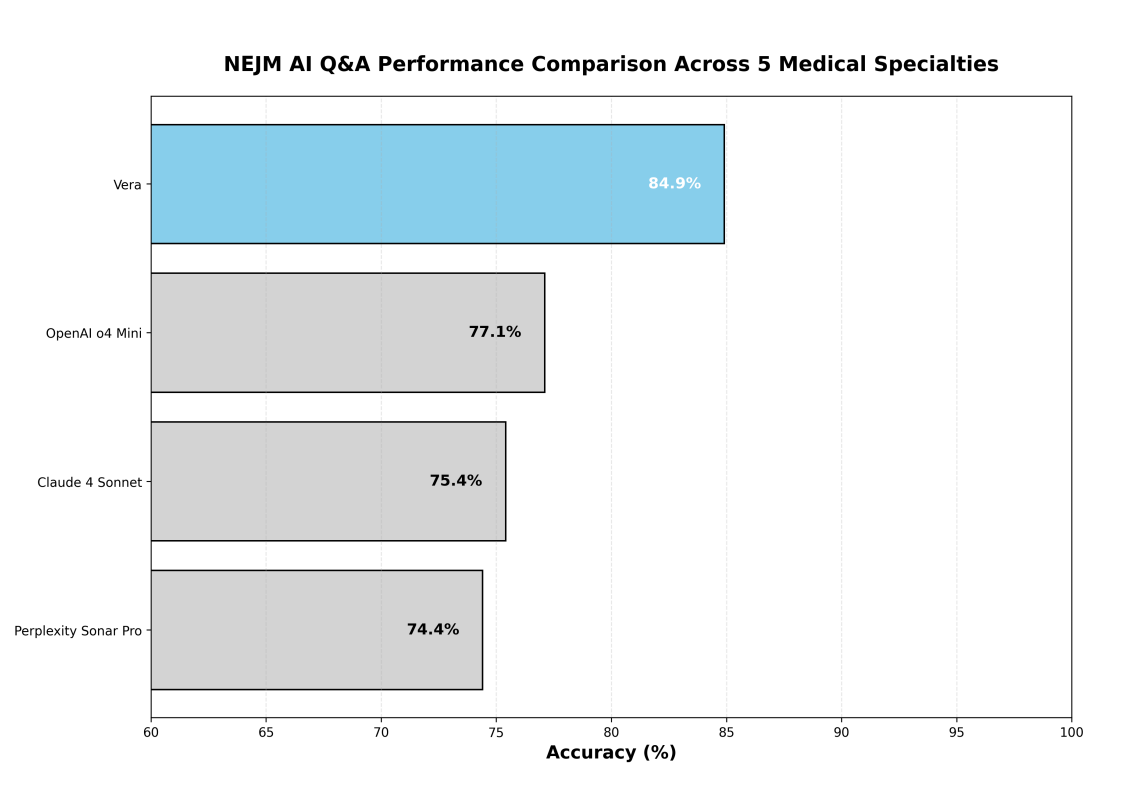
Sur le référentiel NEJM-AI, Vera a atteint l’exactitude globale la plus élevée parmi tous les modèles évalués, surpassant les principaux systèmes d’IA par des marges substantielles. La Figure 2 illustre la supériorité concurrentielle de Vera.
Analyse des performances par spécialité
Les performances de Vera ont varié selon les spécialités médicales, avec des résultats systématiquement solides dans la plupart des domaines. Le Tableau 2 présente en détail les exactitudes par spécialité.
| Spécialité médicale | Questions | Exactitude de Vera |
|---|---|---|
| Pédiatrie | 99 | 93.9 % |
| Psychiatrie | 150 | 88.7 % |
| Médecine interne | 126 | 87.3 % |
| Chirurgie générale | 141 | 83.0 % |
| Gynécologie-obstétrique | 139 | 74.1 % |
La Figure 3 fournit une comparaison détaillée des performances de Vera par rapport aux modèles concurrents à travers les cinq spécialités médicales.
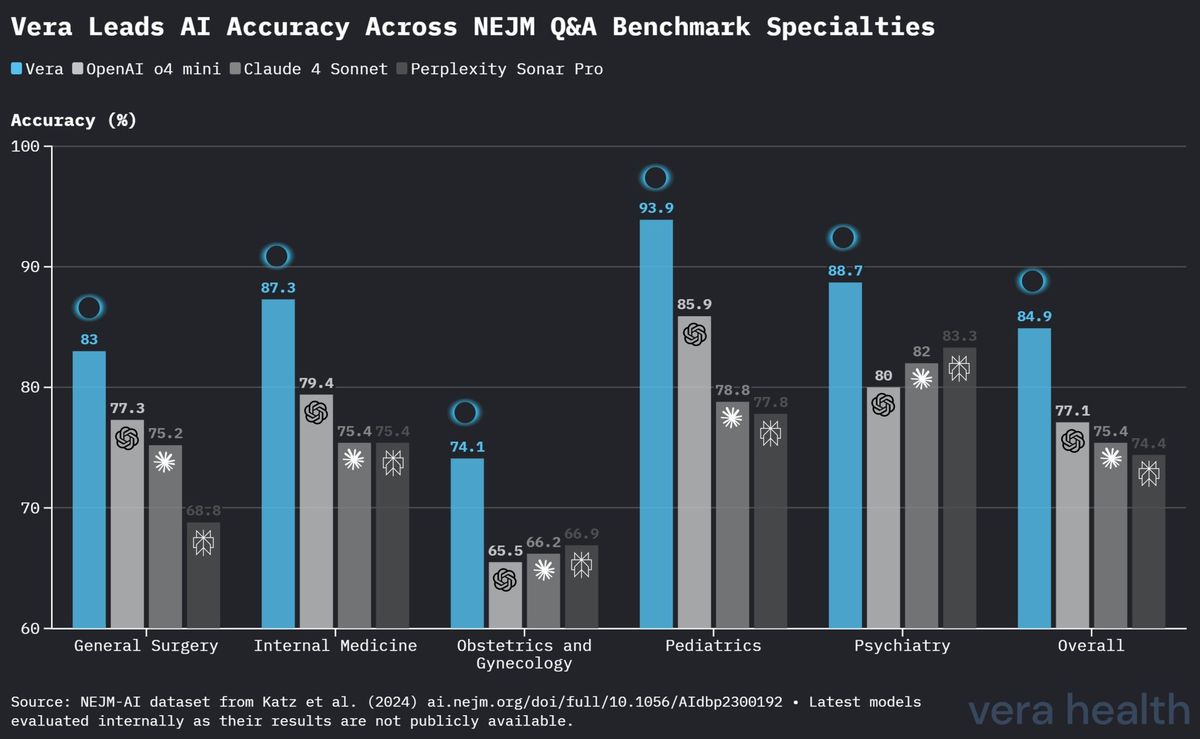
Vera a obtenu l’exactitude la plus élevée dans quatre des cinq spécialités : - Pédiatrie : performances de pointe avec une exactitude de 93.9 % - Médecine interne : performances solides avec une exactitude de 87.3 % - Chirurgie générale : avantage concurrentiel avec une exactitude de 83.0 % - Gynécologie-obstétrique : avance modeste avec une exactitude de 74.1 % - Psychiatrie : performances solides avec une exactitude de 88.7 %
Analyse des performances sur MedXpertQA
Sur le référentiel MedXpertQA, Vera a atteint une exactitude de 62.2 % sur 500 questions médicales variées, démontrant des performances compétentes dans des scénarios de raisonnement clinique spécialisé. Le Tableau 3 présente en détail la répartition des performances selon différentes catégories.
| Catégorie | Questions | Exactitude de Vera |
|---|---|---|
| Par système corporel | ||
| Tégumentaire | 16 | 81.2 % |
| Squelettique | 81 | 72.8 % |
| Musculaire | 36 | 72.2 % |
| Reproducteur | 31 | 71.0 % |
| Digestif | 60 | 63.3 % |
| Endocrinien | 37 | 62.2 % |
| Lymphatique | 22 | 59.1 % |
| Nerveux | 72 | 56.9 % |
| Respiratoire | 32 | 56.2 % |
| Urinaire | 18 | 55.6 % |
| Cardiovasculaire | 68 | 51.5 % |
| Autre/N.D. | 27 | 48.1 % |
| Par tâche médicale | ||
| Sciences fondamentales | 139 | 66.9 % |
| Traitement | 157 | 61.8 % |
| Diagnostic | 204 | 59.3 % |
| Par type de question | ||
| Compréhension | 115 | 66.1 % |
| Raisonnement | 385 | 61.0 % |
Les résultats sur MedXpertQA révèlent plusieurs tendances notables dans les performances de Vera : - Variation selon le système corporel : les performances se sont échelonnées de 81.2 % (Tégumentaire) à 48.1 % (Autre/N.D.), avec les meilleures performances dans les systèmes anatomiquement bien délimités - Performances par tâche médicale : les questions de Sciences fondamentales (66.9 %) ont surpassé les applications cliniques, suggérant de meilleures performances sur les connaissances fondamentales - Analyse par type de question : les questions de Compréhension (66.1 %) ont affiché des performances supérieures à celles des questions de Raisonnement (61.0 %), indiquant des capacités efficaces de récupération des connaissances
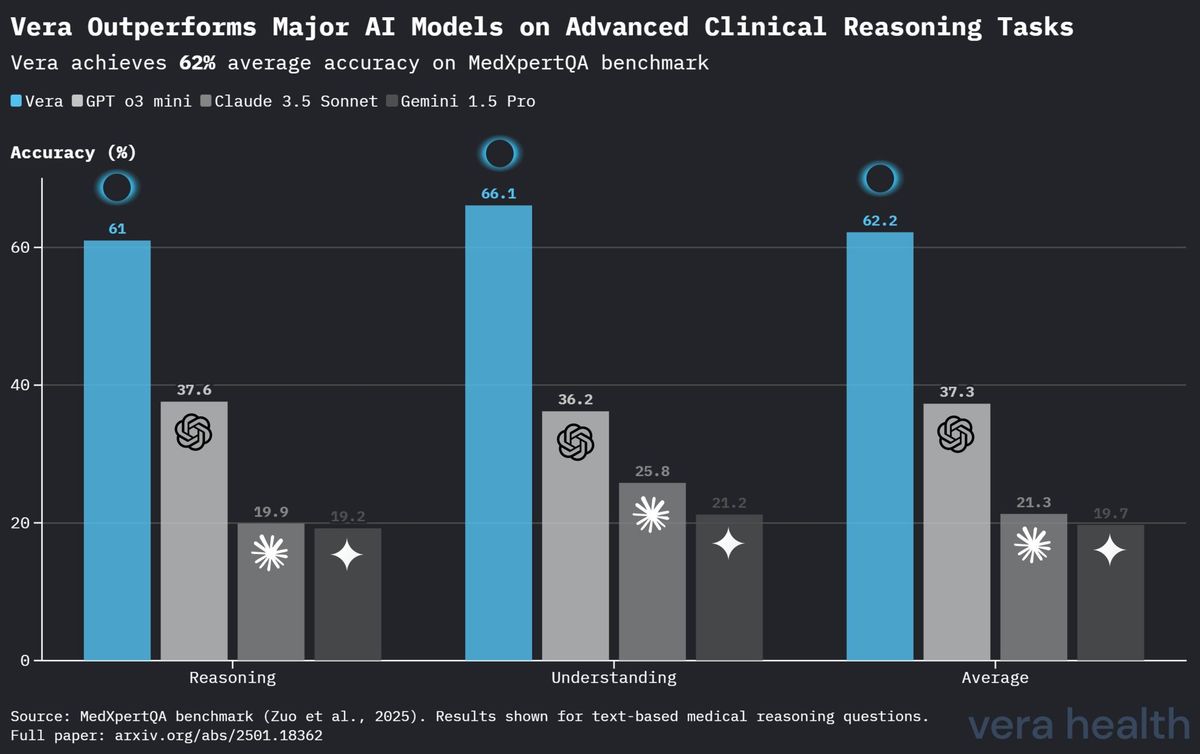
Comparaison des performances des modèles sur MedXpertQA
Le Tableau 4 présente une analyse comparative des performances de Vera par rapport à d’autres modèles d’IA de premier plan sur le référentiel MedXpertQA, mettant en évidence le positionnement concurrentiel de Vera dans les tâches de raisonnement clinique spécialisé.
| Modèle | Raisonnement | Compréhension | Moyenne |
|---|---|---|---|
| Vera | 61.0 % | 66.1 % | 62.2 % |
| OpenAI o3 Mini | 37.6 % | 36.2 % | 37.3 % |
| Claude 3.5 Sonnet | 19.9 % | 25.8 % | 21.3 % |
| Gemini 1.5 Pro | 19.2 % | 21.2 % | 19.7 % |
Méthodes
Cadre d’évaluation
Nous avons mené une évaluation complète multi-référentiels à l’aide de trois cadres distincts d’évaluation des connaissances médicales : l’examen de licence médicale des États-Unis (USMLE), le jeu de données de questions-réponses du New England Journal of Medicine consacré à l’IA (NEJM-AI) et le référentiel MedXpertQA. Cette approche à trois référentiels permet d’évaluer les connaissances médicales fondamentales, les capacités de raisonnement clinique contemporain et l’expertise dans des domaines cliniques spécialisés.
Évaluation USMLE
Nous avons échantillonné des questions à choix multiples issues de ressources officielles de préparation à l’USMLE couvrant les trois étapes de l’examen : Step 1 (sciences fondamentales), Step 2 Clinical Knowledge (connaissances et compétences cliniques) et Step 3 (prise en charge des patients). Chaque question comprenait une vignette clinique, plusieurs options de réponse, une clé de réponse de référence et une classification par spécialité. Les questions ont été présentées à Vera exactement telles qu’elles étaient rédigées, en utilisant le prompt système de production sans optimisation propre au référentiel.
Évaluation sur le référentiel NEJM-AI
Le jeu de données NEJM-AI (Katz et al., 2024) se compose de 655 questions à choix multiples à orientation clinique réparties sur cinq grandes spécialités médicales : Chirurgie générale (141 questions), Médecine interne (126 questions), Gynécologie-obstétrique (139 questions), Pédiatrie (99 questions) et Psychiatrie (150 questions). Ce référentiel a été conçu pour évaluer les connaissances et les capacités de raisonnement cliniques contemporaines pertinentes pour les médecins en exercice. L’étude originale rapportait que GPT-4 atteignait une exactitude de 74.7 % sur ce référentiel.
Évaluation sur le référentiel MedXpertQA
Le jeu de données MedXpertQA (Zuo et al., 2025) est un référentiel particulièrement exigeant, conçu pour évaluer le raisonnement et la compréhension médicaux de niveau expert. Comprenant 4 460 questions couvrant 17 spécialités médicales et 11 systèmes corporels, MedXpertQA constitue l’une des évaluations du raisonnement médical les plus complètes et les plus difficiles disponibles. Le référentiel comprend deux sous-ensembles : MedXpertQA Text pour l’évaluation médicale fondée sur le texte et MedXpertQA MM pour l’évaluation médicale multimodale.
Pour notre évaluation, nous avons utilisé un échantillon représentatif de 500 questions issues du sous-ensemble MedXpertQA Text, en maintenant les normes rigoureuses du référentiel tout en permettant une évaluation efficace. Les questions sont catégorisées par système corporel (12 catégories), tâche médicale (Sciences fondamentales, Diagnostic, Traitement) et type de question (Compréhension, Raisonnement). Ce référentiel évalue les connaissances et capacités de raisonnement cliniques spécialisées à travers un large éventail de scénarios médicaux, des sciences fondamentales aux applications cliniques complexes, ce qui le rend particulièrement précieux pour évaluer les systèmes d’IA médicale avancés.
Protocole expérimental
Pour les trois référentiels, nous avons maintenu des protocoles d’évaluation cohérents : - Toutes les questions ont été présentées à Vera en utilisant le prompt système de production standard, sans ingénierie de prompt propre au référentiel - Le mode optionnel Deep Dive a été désactivé afin de reproduire le mode de réponse rapide privilégié par les cliniciens en conditions réelles - Chaque question a été traitée indépendamment, sans contexte préalable ni optimisation propre à la question - L’exactitude des réponses a été déterminée par correspondance exacte avec les réponses de référence fournies
Analyse concurrentielle
Pour le référentiel NEJM-AI, nous avons comparé les performances de Vera à celles de trois systèmes d’IA médicale de premier plan : OpenAI o4 Mini, Claude 4 Sonnet et Perplexity Sonar Pro. Les modèles les plus récents d’OpenAI, Anthropic et Perplexity n’étant pas accessibles publiquement, nous avons mené des évaluations internes à l’aide de nos propres implémentations. Tous les modèles ont été évalués sur le même ensemble de 655 questions en utilisant leurs configurations optimales respectives. Bien que l’étude originale NEJM-AI rapportait que GPT-4 atteignait une exactitude de 74.7 %, nous l’avons exclu de notre analyse comparative car OpenAI o4 Mini a démontré des performances supérieures.
Analyse statistique
Nous avons calculé les taux d’exactitude globaux, les indicateurs de performance par spécialité et les classements comparatifs. Les variations de performance entre spécialités ont été analysées afin d’identifier les points forts propres à chaque domaine et les axes d’amélioration.
Discussion
Complémentarité des référentiels et implications cliniques
L’évaluation à trois référentiels révèle des éclairages distincts mais complémentaires sur les capacités de Vera. Les performances exceptionnelles sur l’USMLE (exactitude de 97.5 %) démontrent une maîtrise des connaissances médicales fondamentales à travers les domaines des sciences fondamentales, des connaissances cliniques et de la prise en charge des patients. Les solides performances sur le NEJM-AI (exactitude de 84.9 %), avec une supériorité concurrentielle sur les principaux modèles d’IA, indiquent de robustes capacités dans des scénarios de raisonnement clinique contemporain. Les performances sur MedXpertQA (exactitude de 62.2 %) fournissent des éclairages sur l’expertise dans des domaines cliniques spécialisés et sur le raisonnement à travers divers systèmes corporels et tâches médicales.
L’écart de performance entre les référentiels (97.5 % contre 84.9 % contre 62.2 %) reflète vraisemblablement la nature et la complexité distinctes de ces évaluations. Les questions de l’USMLE évaluent principalement des connaissances médicales standardisées assorties de clés de réponse établies, tandis que les questions du NEJM-AI présentent des scénarios cliniques plus nuancés pouvant admettre plusieurs approches raisonnables. MedXpertQA constitue l’évaluation la plus exigeante, mettant en jeu des scénarios de raisonnement clinique complexes qui nécessitent l’intégration de connaissances spécialisées à travers de multiples domaines, ce qui en fait un test rigoureux de compétence clinique avancée.
Positionnement concurrentiel
Les performances de Vera sur le référentiel NEJM-AI établissent des avantages concurrentiels nets sur les systèmes d’IA médicale actuels. L’avance substantielle sur les modèles concurrents représente une amélioration significative dans un domaine très compétitif. Plus important encore, la supériorité constante de Vera dans quatre des cinq spécialités médicales démontre des connaissances cliniques étendues plutôt qu’une optimisation propre à un domaine.
Les résultats par spécialité révèlent des éclairages importants : - Pédiatrie : l’exactitude exceptionnelle de 93.9 % suggère de solides performances dans un domaine exigeant des considérations spécialisées liées au développement et à l’âge - Médecine interne : l’exactitude de 87.3 % démontre une compétence dans le raisonnement étendu requis par cette spécialité fondamentale - Gynécologie-obstétrique : l’exactitude comparativement plus faible de 74.1 %, tout en demeurant en tête des concurrents, indique des axes potentiels d’amélioration ciblée
Généralisation et robustesse du système
Les performances élevées et constantes à travers divers cadres d’évaluation suggèrent que les mécanismes de représentation des connaissances et de raisonnement de Vera se généralisent efficacement à travers différents formats de questions, niveaux de difficulté et contextes cliniques. Cette robustesse est particulièrement importante pour le déploiement clinique, où le système doit gérer des types de requêtes et des scénarios cliniques variés.
Limites et considérations
Malgré ces résultats encourageants, plusieurs limites méritent d’être prises en compte : 1. Portée des référentiels : les deux évaluations reposent sur des formats à choix multiples qui peuvent ne pas saisir pleinement la complexité de la prise de décision clinique du monde réel, laquelle implique souvent de l’incertitude, des informations incomplètes et des présentations cliniques aux multiples facettes. 2. Connaissances cliniques contre connaissances académiques : des performances élevées sur des référentiels académiques ne garantissent pas une efficacité clinique optimale en conditions réelles. La conception de Vera privilégie les recommandations cliniques contemporaines et la pratique fondée sur les preuves, qui peuvent occasionnellement diverger des clés de réponse historiques des examens. 3. Variation selon la spécialité : la variation de performance observée entre les spécialités médicales suggère que certains domaines pourraient bénéficier d’une amélioration ciblée, en particulier la Gynécologie-obstétrique où les performances, bien que compétitives, présentaient la plus grande marge d’amélioration. 4. Considérations temporelles : les connaissances médicales évoluent rapidement au gré des nouvelles découvertes de recherche et des mises à jour des recommandations. Une évaluation continue et une mise à jour du modèle seront essentielles pour maintenir les performances dans le temps. 5. Méthodologie d’évaluation : les deux référentiels reposent sur des clés de réponse prédéterminées qui peuvent ne pas toujours refléter l’ensemble du spectre des réponses cliniquement acceptables, ce qui peut sous-estimer les performances du système dans des scénarios ambigus.
Conclusions
Cette évaluation complète multi-référentiels démontre les capacités exceptionnelles de Vera à travers divers domaines de connaissances médicales. Le système a atteint une exactitude quasi parfaite sur l’USMLE (97.5 %), établi une supériorité concurrentielle sur le référentiel NEJM-AI (84.9 %) et démontré des performances compétentes sur l’exigeant référentiel MedXpertQA (62.2 %). Sur le NEJM-AI, Vera a surpassé les principaux modèles d’IA, notamment OpenAI o4 Mini, Claude 4 Sonnet et Perplexity Sonar Pro.
Les principaux résultats comprennent : - Compétence médicale étendue : des performances élevées et constantes à travers les domaines de connaissances fondamentales (USMLE), cliniques contemporaines (NEJM-AI) et de raisonnement spécialisé (MedXpertQA) - Avantage concurrentiel : une supériorité nette sur les systèmes d’IA médicale actuels lors d’une comparaison directe - Robustesse par spécialité : des performances de pointe dans quatre des cinq spécialités médicales du NEJM-AI, avec des résultats particulièrement solides en Pédiatrie et en Médecine interne - Expertise propre au domaine : de solides performances à travers divers systèmes corporels dans MedXpertQA, avec une force particulière dans les systèmes anatomiquement bien délimités (Tégumentaire : 81.2 %, Squelettique : 72.8 %) - Généralisation des connaissances : des performances efficaces à travers divers formats de questions, niveaux de difficulté et contextes cliniques
Ces résultats positionnent Vera comme une solution de premier plan pour l’aide à la décision clinique, avec des capacités démontrées qui dépassent les référentiels actuels pour les systèmes d’IA médicale. L’approche à trois référentiels fournit des preuves solides des performances du système à travers des scénarios académiques, cliniquement pertinents et de raisonnement spécialisé, soutenant un déploiement dans la formation médicale, la formation clinique et les applications d’aide à la décision au point de soins.
Disponibilité des données
Les jeux de données d’évaluation et les résultats détaillés sont disponibles sur demande (enterprise@vera-health.ai) et seront fournis sous réserve des accords standards d’utilisation des données et des garanties de confidentialité.
Références
[1] Katz, U., Cohen, E., Shachar, E., Somer, J., Fink, A., Morse, E., Shreiber, B., & Wolf, I. (2024). GPT versus Resident Physicians — A Benchmark Based on Official Board Scores. NEJM AI, 1(5), AIdbp2300192. https://doi.org/10.1056/AIdbp2300192 [2] Zuo, Y., Qu, S., Li, Y., Chen, Z., Zhu, X., Hua, E., Zhang, K., Ding, N., & Zhou, B. (2025). MedXpertQA: Benchmarking expert-level medical reasoning and understanding. arXiv preprint arXiv:2501.18362. [3] Bicknell, B. T., Butler, D., Whalen, S., Ricks, J., Dixon, C. J., Clark, A. B., Spaedy, O., Skelton, A., Edupuganti, N., Dzubinski, L., Tate, H., Dyess, G., Lindeman, B., & Lehmann, L. S. (2024). ChatGPT-4 Omni Performance in USMLE Disciplines and Clinical Skills: Comparative Analysis. JMIR medical education, 10, e63430. https://doi.org/10.2196/63430
À propos de Vera Health
Vera est un outil d’aide à la décision clinique (CDS) propulsé par l’IA, conçu pour aider les professionnels de santé à prendre des décisions fondées sur les preuves de manière plus efficace. Vera s’appuie sur des agents d’IA sophistiqués et sur la technologie de génération augmentée par récupération (Retrieval-Augmented Generation), en synthétisant les connaissances issues de plus de 60 millions de publications médicales évaluées par les pairs afin de fournir des réponses fiables et adaptées au contexte au point de soins. Grâce à sa technologie d’IA de pointe, Vera permet aux cliniciens d’améliorer les résultats des patients et de rationaliser les processus de prise de décision.


