
Valutazione completa delle prestazioni di Vera: un'analisi multi-benchmark attraverso i domini della conoscenza medica
Sintesi
Presentiamo una valutazione completa di Vera, un sistema avanzato di supporto alle decisioni cliniche progettato per fornire agli operatori sanitari una guida medica istantanea e basata sull'evidenza. Vera sfrutta sofisticati agenti di IA e la tecnologia di Retrieval-Augmented Generation, sintetizzando conoscenze provenienti da oltre 60 milioni di pubblicazioni mediche sottoposte a revisione paritaria per fornire risposte affidabili e contestualmente appropriate. Questa analisi multi-benchmark valuta le prestazioni di Vera attraverso tre distinti domini della conoscenza medica: lo United States Medical Licensing Examination (USMLE), il dataset di domande e risposte di IA del New England Journal of Medicine (NEJM-AI) e il benchmark MedXpertQA. Sull'USMLE, Vera ha raggiunto un'accuratezza complessiva eccezionale del 97.5 %, con accuratezze specifiche per step del 97.9 % (Step 1), del 98.2 % (Step 2 CK) e del 96.7 % (Step 3). Sul benchmark NEJM-AI, composto da 655 domande in cinque specialità mediche, Vera ha dimostrato prestazioni superiori con un'accuratezza dell'84.9 %, superando i principali modelli di IA, tra cui OpenAI o4 Mini (77.1 %), Claude 4 Sonnet (75.4 %) e Perplexity Sonar Pro (74.4 %). Sul benchmark MedXpertQA, composto da 500 domande su molteplici sistemi corporei e compiti medici, Vera ha raggiunto un'accuratezza del 62.2 %, dimostrando prestazioni solide in scenari di ragionamento clinico specializzato. Vera ha raggiunto l'accuratezza più elevata in quattro delle cinque specialità mediche del NEJM-AI, con prestazioni particolarmente solide in Pediatria (93.9 %) e Medicina interna (87.3 %). Questi risultati attraverso diversi quadri di valutazione sottolineano la robusta rappresentazione della conoscenza medica e le capacità di ragionamento di Vera, posizionandola come una soluzione di primo piano per il supporto alle decisioni cliniche.
Introduzione
Gli operatori sanitari in diversi contesti clinici necessitano di un accesso rapido a conoscenze mediche accurate e basate sull'evidenza per supportare un'assistenza ottimale ai pazienti. La crescita esponenziale della letteratura medica presenta sfide senza precedenti per il recupero e la sintesi tempestivi delle conoscenze. Vera risponde a questa esigenza critica combinando sofisticati agenti di IA con l'avanzata tecnologia di Retrieval-Augmented Generation, fornendo una guida clinica affidabile circa dieci volte più velocemente rispetto ai metodi convenzionali.
La valutazione dei sistemi di IA medica richiede un'analisi rigorosa attraverso molteplici domini per garantire prestazioni robuste in scenari clinici reali. Sebbene i singoli benchmark forniscano spunti preziosi, una valutazione completa attraverso diversi quadri di conoscenza offre un quadro più completo delle capacità e dei limiti del sistema. Questo studio presenta una valutazione multi-benchmark di Vera utilizzando tre quadri di valutazione complementari: lo United States Medical Licensing Examination (USMLE), il dataset di domande e risposte di IA del New England Journal of Medicine (NEJM-AI) e il benchmark MedXpertQA.
L'USMLE fornisce una misura standardizzata della conoscenza medica fondamentale attraverso i domini della scienza di base, della conoscenza clinica e della gestione del paziente. Tuttavia, riflette principalmente contenuti formativi pre-abilitazione e potrebbe non cogliere appieno la complessità del processo decisionale clinico contemporaneo. Per affrontare questa limitazione, integriamo la nostra valutazione con il benchmark NEJM-AI, che presenta 655 domande a orientamento clinico attraverso cinque principali specialità mediche, offrendo spunti sulle prestazioni in scenari più rilevanti per la pratica. Inoltre, valutiamo Vera sul benchmark MedXpertQA, composto da 500 domande che valutano il ragionamento clinico attraverso diversi sistemi corporei, compiti medici e tipi di domanda, fornendo ulteriori spunti sui domini di conoscenza clinica specializzata.
La nostra analisi completa attraverso questi distinti quadri di valutazione rivela i punti di forza e le caratteristiche prestazionali di Vera, dimostrando una notevole promessa nel trasformare il supporto alle decisioni cliniche, nel migliorare l'efficienza degli operatori e, in ultima analisi, nel migliorare la qualità dell'assistenza ai pazienti.
Risultati
Panoramica delle prestazioni multi-benchmark
Vera ha dimostrato prestazioni eccezionali attraverso tutti e tre i quadri di valutazione, raggiungendo il 97.5% sull'USMLE, l'84.9% sul benchmark NEJM-AI e il 62.2% sul benchmark MedXpertQA. La Tabella 1 riassume le prestazioni di Vera attraverso tutte le valutazioni.
| Benchmark | Accuratezza |
|---|---|
| USMLE (complessivo) | 97.5 % |
| Step 1 | 97.9 % |
| Step 2 CK | 98.2 % |
| Step 3 | 96.7 % |
| NEJM-AI (complessivo) | 84.9 % |
| MedXpertQA (complessivo) | 62.2 % |
Analisi delle prestazioni sull'USMLE
Nella valutazione USMLE, Vera ha raggiunto un'accuratezza quasi perfetta attraverso tutti i livelli d'esame, dimostrando una robusta conoscenza medica fondamentale. La minima variazione tra gli step (intervallo: 96.7–98.2 %) indica che la rappresentazione della conoscenza di Vera si adatta efficacemente dai concetti di scienza di base agli scenari clinici complessi che richiedono decisioni di gestione del paziente.
Analisi competitiva sull'USMLE
Le prestazioni di Vera stabiliscono una chiara superiorità rispetto ad altri sistemi di IA medica nella valutazione standardizzata della conoscenza medica. La Figura 1 dimostra il vantaggio competitivo di Vera nel panorama dell'IA medica.
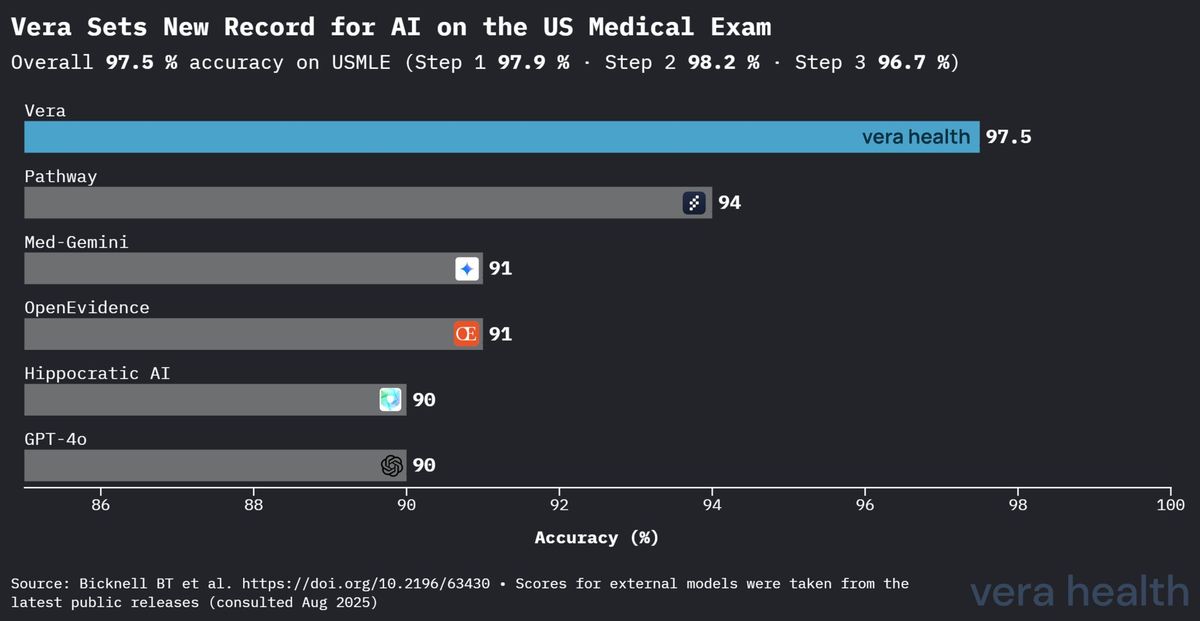
Questa analisi competitiva rivela diversi spunti chiave: (1) il vantaggio di 3,5 punti percentuali di Vera rispetto al secondo modello con le migliori prestazioni rappresenta un miglioramento sostanziale nella valutazione della conoscenza medica; (2) il divario prestazionale si amplia significativamente rispetto ai modelli di uso generale, evidenziando il valore dell'ottimizzazione specifica per l'ambito medico; e (3) la superiorità di Vera si estende sia ai sistemi di IA medica specializzata sia ai principali modelli linguistici di uso generale.
Risultati del benchmark competitivo NEJM-AI
Sul benchmark NEJM-AI, Vera ha raggiunto l'accuratezza complessiva più elevata tra tutti i modelli valutati, superando i principali sistemi di IA con margini sostanziali. La Figura 2 dimostra la superiorità competitiva di Vera.
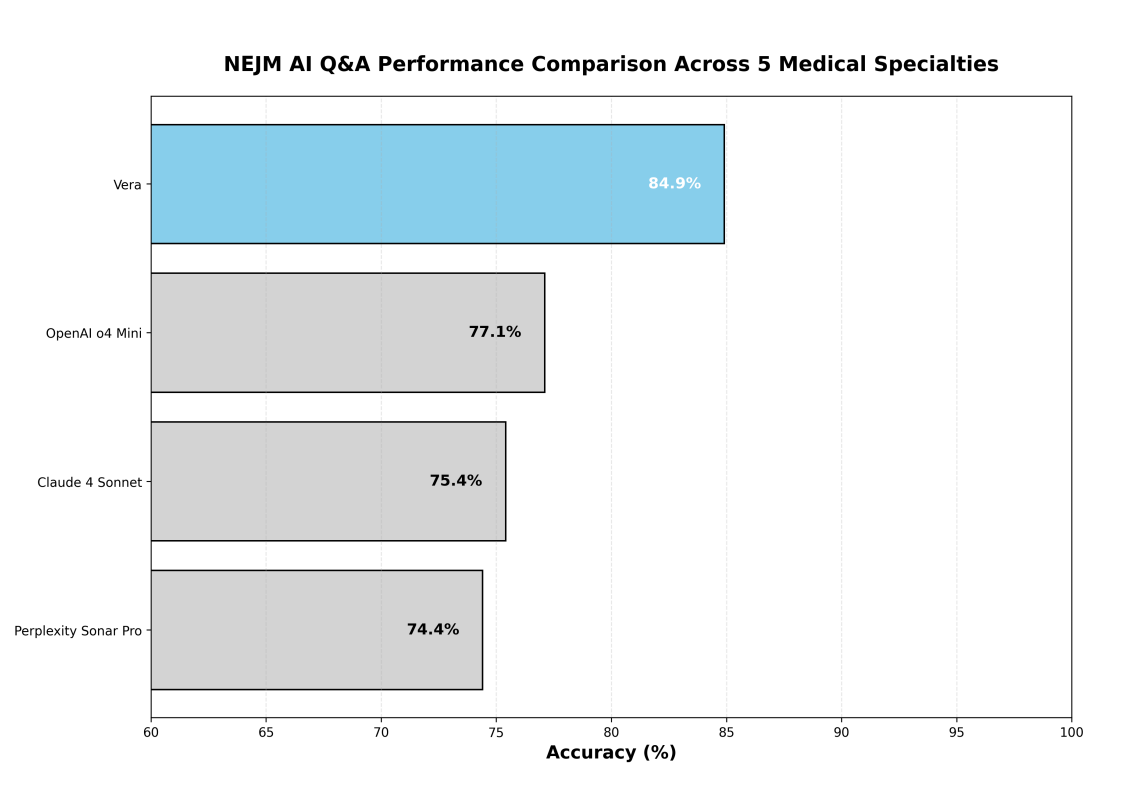
Analisi delle prestazioni specifiche per specialità
Le prestazioni di Vera hanno variato tra le specialità mediche, con risultati costantemente solidi nella maggior parte dei domini. La Tabella 2 presenta le accuratezze dettagliate specifiche per specialità.
| Specialità medica | Domande | Accuratezza di Vera |
|---|---|---|
| Pediatria | 99 | 93.9 % |
| Psichiatria | 150 | 88.7 % |
| Medicina interna | 126 | 87.3 % |
| Chirurgia generale | 141 | 83.0 % |
| Ginecologia e ostetricia | 139 | 74.1 % |
La Figura 3 fornisce un confronto dettagliato delle prestazioni di Vera rispetto ai modelli concorrenti attraverso tutte e cinque le specialità mediche.
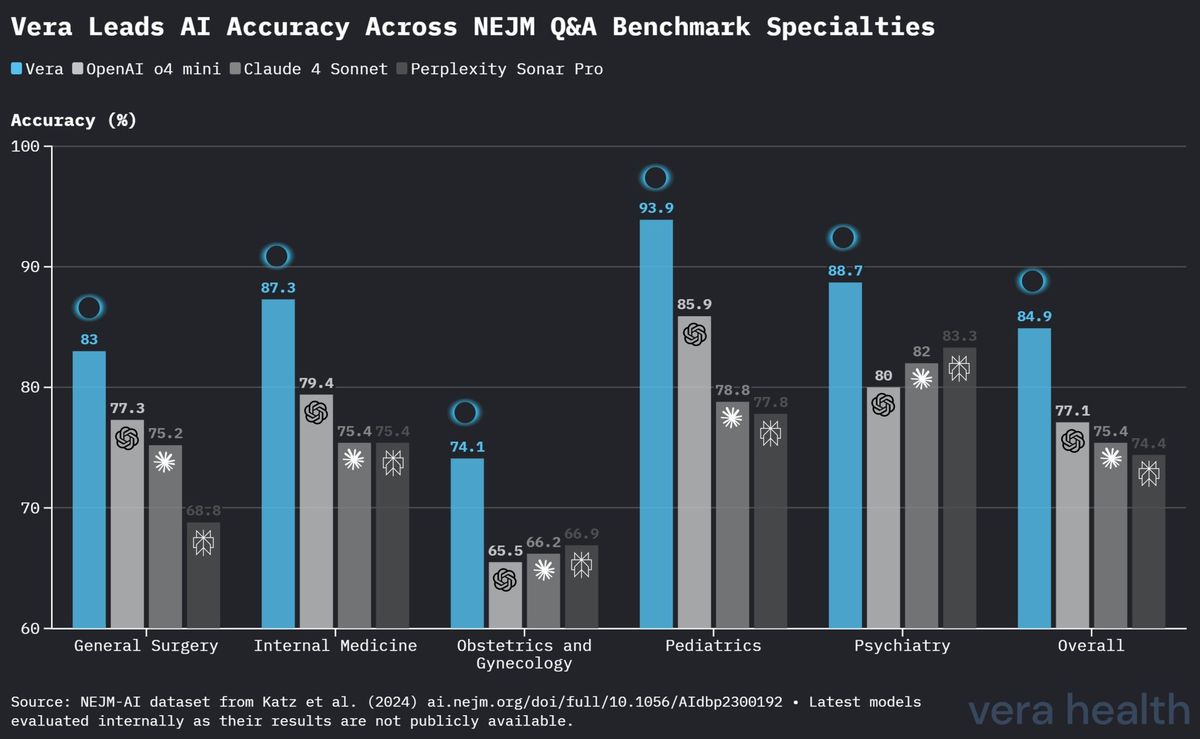
Vera ha raggiunto l'accuratezza più elevata in quattro delle cinque specialità: - Pediatria: prestazioni di primo piano con un'accuratezza del 93.9 % - Medicina interna: prestazioni solide con un'accuratezza dell'87.3 % - Chirurgia generale: vantaggio competitivo con un'accuratezza dell'83.0 % - Ginecologia e ostetricia: modesto vantaggio con un'accuratezza del 74.1 % - Psichiatria: prestazioni solide con un'accuratezza dell'88.7 %
Analisi delle prestazioni sul MedXpertQA
Sul benchmark MedXpertQA, Vera ha raggiunto un'accuratezza del 62.2 % su 500 diverse domande mediche, dimostrando prestazioni competenti in scenari di ragionamento clinico specializzato. La Tabella 3 presenta le ripartizioni dettagliate delle prestazioni attraverso le diverse categorie.
| Categoria | Domande | Accuratezza di Vera |
|---|---|---|
| Per sistema corporeo | ||
| Tegumentario | 16 | 81.2 % |
| Scheletrico | 81 | 72.8 % |
| Muscolare | 36 | 72.2 % |
| Riproduttivo | 31 | 71.0 % |
| Digerente | 60 | 63.3 % |
| Endocrino | 37 | 62.2 % |
| Linfatico | 22 | 59.1 % |
| Nervoso | 72 | 56.9 % |
| Respiratorio | 32 | 56.2 % |
| Urinario | 18 | 55.6 % |
| Cardiovascolare | 68 | 51.5 % |
| Altro/N.D. | 27 | 48.1 % |
| Per compito medico | ||
| Scienza di base | 139 | 66.9 % |
| Trattamento | 157 | 61.8 % |
| Diagnosi | 204 | 59.3 % |
| Per tipo di domanda | ||
| Comprensione | 115 | 66.1 % |
| Ragionamento | 385 | 61.0 % |
I risultati del MedXpertQA rivelano diversi schemi degni di nota nelle prestazioni di Vera: - Variazione per sistema corporeo: le prestazioni hanno spaziato dall'81.2 % (Tegumentario) al 48.1 % (Altro/N.D.), con le prestazioni più solide nei sistemi anatomicamente distinti - Prestazioni per compito medico: le domande di Scienza di base (66.9 %) hanno superato le applicazioni cliniche, suggerendo prestazioni più solide sulla conoscenza fondamentale - Analisi per tipo di domanda: le domande di Comprensione (66.1 %) hanno mostrato prestazioni superiori rispetto alle domande di Ragionamento (61.0 %), indicando efficaci capacità di recupero della conoscenza
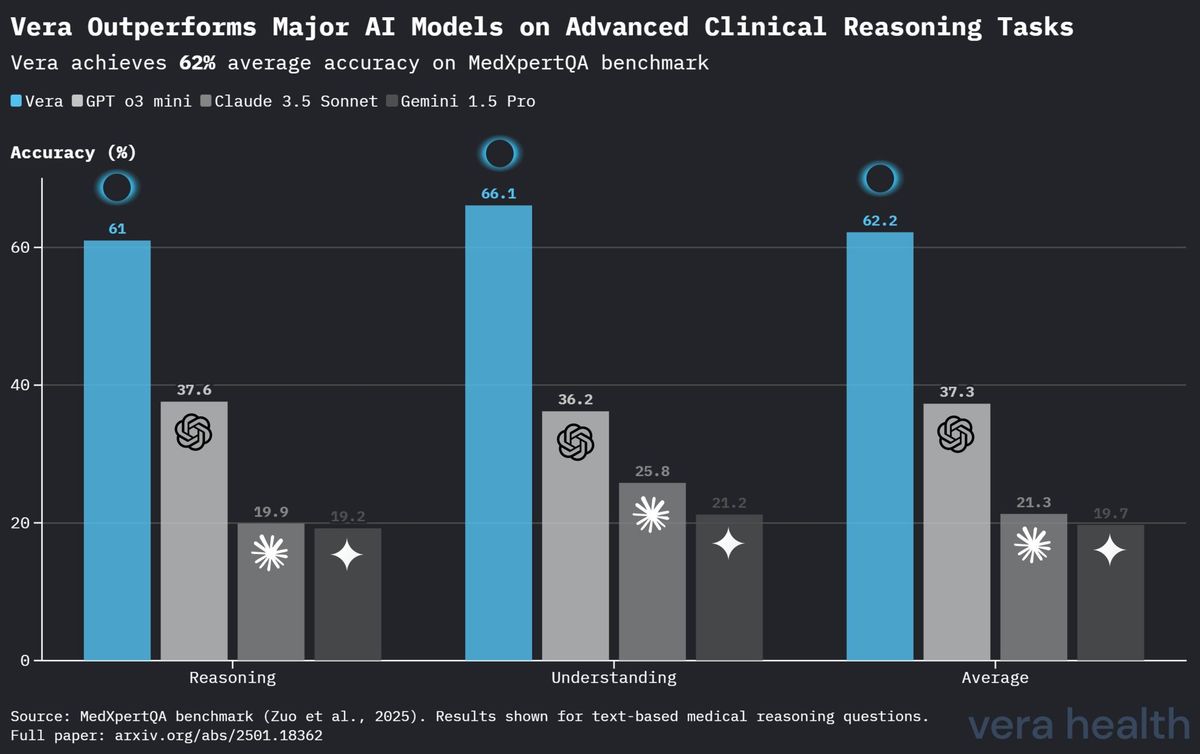
Confronto delle prestazioni dei modelli sul MedXpertQA
La Tabella 4 presenta un'analisi comparativa delle prestazioni di Vera rispetto ad altri modelli di IA di primo piano sul benchmark MedXpertQA, evidenziando il posizionamento competitivo di Vera nei compiti di ragionamento clinico specializzato.
| Modello | Ragionamento | Comprensione | Media |
|---|---|---|---|
| Vera | 61.0 % | 66.1 % | 62.2 % |
| OpenAI o3 Mini | 37.6 % | 36.2 % | 37.3 % |
| Claude 3.5 Sonnet | 19.9 % | 25.8 % | 21.3 % |
| Gemini 1.5 Pro | 19.2 % | 21.2 % | 19.7 % |
Metodi
Quadro di valutazione
Abbiamo condotto una valutazione completa multi-benchmark utilizzando tre distinti quadri di valutazione della conoscenza medica: lo United States Medical Licensing Examination (USMLE), il dataset di domande e risposte di IA del New England Journal of Medicine (NEJM-AI) e il benchmark MedXpertQA. Questo approccio tri-benchmark consente la valutazione della conoscenza medica fondamentale, delle capacità di ragionamento clinico contemporaneo e dell'expertise in domini clinici specializzati.
Valutazione USMLE
Abbiamo campionato domande a scelta multipla da risorse ufficiali di preparazione all'USMLE che coprono tutti e tre gli step d'esame: Step 1 (scienza di base), Step 2 Clinical Knowledge (conoscenze e abilità cliniche) e Step 3 (gestione del paziente). Ciascuna domanda comprendeva una vignetta clinica, molteplici opzioni di risposta, una chiave di risposta di riferimento e una classificazione per specialità. Le domande sono state presentate a Vera esattamente come formulate, utilizzando il system prompt di produzione senza ottimizzazione specifica per il benchmark.
Valutazione del benchmark NEJM-AI
Il dataset NEJM-AI (Katz et al., 2024) è composto da 655 domande a scelta multipla a orientamento clinico distribuite tra cinque principali specialità mediche: Chirurgia generale (141 domande), Medicina interna (126 domande), Ginecologia e ostetricia (139 domande), Pediatria (99 domande) e Psichiatria (150 domande). Questo benchmark è stato progettato per valutare la conoscenza clinica contemporanea e le capacità di ragionamento rilevanti per i medici praticanti. Lo studio originale ha riportato che GPT-4 ha raggiunto un'accuratezza del 74.7% su questo benchmark.
Valutazione del benchmark MedXpertQA
Il dataset MedXpertQA (Zuo et al., 2025) è un benchmark altamente impegnativo progettato per valutare il ragionamento e la comprensione medica a livello di esperto. Composto da 4.460 domande che coprono 17 specialità mediche e 11 sistemi corporei, MedXpertQA rappresenta una delle valutazioni del ragionamento medico più complete e difficili disponibili. Il benchmark include due sottoinsiemi: MedXpertQA Text per la valutazione medica basata su testo e MedXpertQA MM per la valutazione medica multimodale.
Per la nostra valutazione, abbiamo utilizzato un campione rappresentativo di 500 domande dal sottoinsieme MedXpertQA Text, mantenendo i rigorosi standard del benchmark e consentendo al contempo una valutazione efficiente. Le domande sono categorizzate per sistema corporeo (12 categorie), compito medico (Scienza di base, Diagnosi, Trattamento) e tipo di domanda (Comprensione, Ragionamento). Questo benchmark valuta la conoscenza clinica specializzata e le capacità di ragionamento attraverso un ampio spettro di scenari medici, dalla scienza fondamentale alle complesse applicazioni cliniche, rendendolo particolarmente prezioso per la valutazione di sistemi di IA medica avanzati.
Protocollo sperimentale
Per tutti e tre i benchmark, abbiamo mantenuto protocolli di valutazione coerenti: - Tutte le domande sono state presentate a Vera utilizzando il system prompt di produzione standard senza alcuna ingegnerizzazione del prompt specifica per il benchmark - La modalità opzionale Deep Dive è stata disattivata per rispecchiare la modalità a risposta rapida preferita dai clinici nei contesti reali - Ciascuna domanda è stata elaborata in modo indipendente senza contesto precedente o ottimizzazione specifica per la domanda - L'accuratezza delle risposte è stata determinata mediante corrispondenza esatta con le risposte di riferimento fornite
Analisi competitiva
Per il benchmark NEJM-AI, abbiamo confrontato le prestazioni di Vera con tre sistemi di IA medica di primo piano: OpenAI o4 Mini, Claude 4 Sonnet e Perplexity Sonar Pro. Poiché i modelli più recenti di OpenAI, Anthropic e Perplexity non sono pubblicamente disponibili, abbiamo condotto valutazioni interne utilizzando le nostre implementazioni. Tutti i modelli sono stati valutati sull'identico set di 655 domande utilizzando le rispettive configurazioni ottimali. Sebbene lo studio originale NEJM-AI abbia riportato che GPT-4 ha raggiunto un'accuratezza del 74.7%, lo abbiamo escluso dalla nostra analisi comparativa poiché OpenAI o4 Mini ha dimostrato prestazioni superiori.
Analisi statistica
Abbiamo calcolato i tassi di accuratezza complessivi, le metriche di prestazione specifiche per specialità e le classifiche comparative. Le variazioni prestazionali tra le specialità sono state analizzate per identificare i punti di forza specifici per dominio e le aree di miglioramento.
Discussione
Complementarità dei benchmark e implicazioni cliniche
La valutazione tri-benchmark rivela spunti distinti ma complementari sulle capacità di Vera. Le eccezionali prestazioni sull'USMLE (accuratezza del 97.5 %) dimostrano la padronanza della conoscenza medica fondamentale attraverso i domini della scienza di base, della conoscenza clinica e della gestione del paziente. Le solide prestazioni sul NEJM-AI (accuratezza dell'84.9 %) con una superiorità competitiva rispetto ai principali modelli di IA indicano robuste capacità in scenari di ragionamento clinico contemporaneo. Le prestazioni sul MedXpertQA (accuratezza del 62.2 %) forniscono spunti sull'expertise in domini clinici specializzati e sul ragionamento attraverso diversi sistemi corporei e compiti medici.
Il differenziale prestazionale tra i benchmark (97.5 % rispetto a 84.9 % rispetto a 62.2 %) riflette probabilmente la natura e la complessità distinte di queste valutazioni. Le domande dell'USMLE valutano principalmente la conoscenza medica standardizzata con chiavi di risposta consolidate, mentre le domande del NEJM-AI presentano scenari clinici più sfumati che possono ammettere molteplici approcci ragionevoli. MedXpertQA rappresenta la valutazione più impegnativa, presentando complessi scenari di ragionamento clinico che richiedono l'integrazione di conoscenze specializzate attraverso molteplici domini, rendendolo un rigoroso test di competenza clinica avanzata.
Posizionamento competitivo
Le prestazioni di Vera sul benchmark NEJM-AI stabiliscono chiari vantaggi competitivi rispetto agli attuali sistemi di IA medica. Il sostanziale vantaggio rispetto ai modelli concorrenti rappresenta un miglioramento significativo in un ambito altamente competitivo. Ancora più significativamente, la costante superiorità di Vera in quattro delle cinque specialità mediche dimostra una conoscenza clinica ad ampio raggio piuttosto che un'ottimizzazione specifica per dominio.
I risultati specifici per specialità rivelano spunti importanti: - Pediatria: l'eccezionale accuratezza del 93.9 % suggerisce prestazioni solide in un dominio che richiede considerazioni specializzate relative allo sviluppo e all'età - Medicina interna: l'accuratezza dell'87.3 % dimostra competenza nel ragionamento ad ampio raggio richiesto per questa specialità fondamentale - Ginecologia e ostetricia: l'accuratezza comparativamente inferiore del 74.1 %, pur restando in testa rispetto ai concorrenti, indica potenziali aree di miglioramento mirato
Generalizzazione e robustezza del sistema
Le costanti prestazioni elevate attraverso diversi quadri di valutazione suggeriscono che la rappresentazione della conoscenza e i meccanismi di ragionamento di Vera si generalizzano efficacemente attraverso diversi formati di domanda, livelli di difficoltà e contesti clinici. Questa robustezza è particolarmente importante per il dispiegamento clinico, dove il sistema deve gestire diversi tipi di query e scenari clinici.
Limitazioni e considerazioni
Nonostante questi risultati incoraggianti, diverse limitazioni meritano considerazione: 1. Ambito del benchmark: entrambe le valutazioni si basano su formati a scelta multipla che potrebbero non cogliere appieno la complessità del processo decisionale clinico reale, che spesso comporta incertezza, informazioni incomplete e presentazioni del paziente multiformi. 2. Conoscenza clinica rispetto a quella accademica: prestazioni elevate sui benchmark accademici non garantiscono un'efficacia clinica ottimale nel mondo reale. La progettazione di Vera privilegia le linee guida cliniche contemporanee e la pratica basata sull'evidenza, che possono occasionalmente discostarsi dalle chiavi di risposta degli esami storici. 3. Variazione per specialità: la variazione prestazionale osservata tra le specialità mediche suggerisce che alcuni domini potrebbero beneficiare di un potenziamento mirato, in particolare la Ginecologia e ostetricia, dove le prestazioni, pur essendo competitive, hanno mostrato il maggiore margine di miglioramento. 4. Considerazioni temporali: la conoscenza medica evolve rapidamente con nuovi risultati di ricerca e aggiornamenti delle linee guida. La valutazione continua e l'aggiornamento del modello saranno essenziali per mantenere le prestazioni nel tempo. 5. Metodologia di valutazione: entrambi i benchmark si basano su chiavi di risposta predeterminate che potrebbero non sempre riflettere l'intero spettro di risposte clinicamente accettabili, sottostimando potenzialmente le prestazioni del sistema in scenari ambigui.
Conclusioni
Questa completa valutazione multi-benchmark dimostra le eccezionali capacità di Vera attraverso diversi domini della conoscenza medica. Il sistema ha raggiunto un'accuratezza quasi perfetta sull'USMLE (97.5 %), ha stabilito una superiorità competitiva sul benchmark NEJM-AI (84.9 %) e ha dimostrato prestazioni competenti sull'impegnativo benchmark MedXpertQA (62.2 %). Sul NEJM-AI, Vera ha superato i principali modelli di IA, tra cui OpenAI o4 Mini, Claude 4 Sonnet e Perplexity Sonar Pro.
I risultati chiave includono: - Ampia competenza medica: prestazioni costantemente elevate attraverso i domini di conoscenza fondamentale (USMLE), clinica contemporanea (NEJM-AI) e ragionamento specializzato (MedXpertQA) - Vantaggio competitivo: chiara superiorità rispetto agli attuali sistemi di IA medica nel confronto diretto - Robustezza tra specialità: prestazioni di primo piano in quattro delle cinque specialità mediche del NEJM-AI, con risultati particolarmente solidi in Pediatria e Medicina interna - Expertise specifica per dominio: prestazioni solide attraverso diversi sistemi corporei nel MedXpertQA, con particolare forza nei sistemi anatomicamente distinti (Tegumentario: 81.2 %, Scheletrico: 72.8 %) - Generalizzazione della conoscenza: prestazioni efficaci attraverso diversi formati di domanda, livelli di difficoltà e contesti clinici
Questi risultati posizionano Vera come una soluzione di primo piano per il supporto alle decisioni cliniche, con capacità dimostrate che superano gli attuali benchmark per i sistemi di IA medica. L'approccio tri-benchmark fornisce solide evidenze delle prestazioni del sistema attraverso scenari accademici, clinicamente rilevanti e di ragionamento specializzato, supportando il dispiegamento in applicazioni di formazione medica, addestramento clinico e supporto alle decisioni al punto di cura.
Disponibilità dei dati
I dataset di valutazione e i risultati dettagliati sono disponibili su richiesta (enterprise@vera-health.ai) e saranno forniti subordinatamente a standard accordi sull'uso dei dati e tutele della privacy.
Riferimenti bibliografici
[1] Katz, U., Cohen, E., Shachar, E., Somer, J., Fink, A., Morse, E., Shreiber, B., & Wolf, I. (2024). GPT versus Resident Physicians — A Benchmark Based on Official Board Scores. NEJM AI, 1(5), AIdbp2300192. https://doi.org/10.1056/AIdbp2300192 [2] Zuo, Y., Qu, S., Li, Y., Chen, Z., Zhu, X., Hua, E., Zhang, K., Ding, N., & Zhou, B. (2025). MedXpertQA: Benchmarking expert-level medical reasoning and understanding. arXiv preprint arXiv:2501.18362. [3] Bicknell, B. T., Butler, D., Whalen, S., Ricks, J., Dixon, C. J., Clark, A. B., Spaedy, O., Skelton, A., Edupuganti, N., Dzubinski, L., Tate, H., Dyess, G., Lindeman, B., & Lehmann, L. S. (2024). ChatGPT-4 Omni Performance in USMLE Disciplines and Clinical Skills: Comparative Analysis. JMIR medical education, 10, e63430. https://doi.org/10.2196/63430
Informazioni su Vera Health
Vera è uno strumento di supporto alle decisioni cliniche (CDS) basato sull'IA, progettato per assistere gli operatori sanitari nel prendere decisioni basate sull'evidenza in modo più efficiente. Vera sfrutta sofisticati agenti di IA e la tecnologia di Retrieval-Augmented Generation, sintetizzando conoscenze provenienti da oltre 60 milioni di pubblicazioni mediche sottoposte a revisione paritaria per fornire risposte affidabili e contestualmente appropriate al punto di cura. Grazie alla sua tecnologia di IA all'avanguardia, Vera consente ai clinici di migliorare gli esiti dei pazienti e di ottimizzare i processi decisionali.


