
Vera의 종합 성능 평가: 의학 지식 영역 전반에 걸친 다중 벤치마크 평가
초록
본 연구는 의료 제공자에게 즉각적이고 근거 기반의 의학적 지침을 제공하도록 설계된 첨단 임상 의사결정 지원 시스템인 Vera에 대한 종합적 평가를 제시합니다. Vera는 정교한 AI 에이전트와 검색 증강 생성(RAG) 기술을 활용하여 6,000만 건 이상의 동료 심사를 거친 의학 출판물로부터 지식을 종합함으로써 신뢰할 수 있고 맥락에 적합한 답변을 제공합니다. 본 다중 벤치마크 평가는 세 가지 서로 다른 의학 지식 영역, 즉 미국 의사면허시험(USMLE), 뉴잉글랜드 의학저널 AI 질의응답 데이터셋(NEJM-AI), 그리고 MedXpertQA 벤치마크 전반에 걸쳐 Vera의 성능을 평가합니다. USMLE에서 Vera는 97.5 %의 탁월한 전체 정확도를 달성하였으며, 단계별 정확도는 97.9 %(Step 1), 98.2 %(Step 2 CK), 96.7 %(Step 3)였습니다. 다섯 개 의학 전문 분야에 걸친 655개 문항으로 구성된 NEJM-AI 벤치마크에서 Vera는 84.9 %의 정확도로 우수한 성능을 보였으며, OpenAI o4 Mini(77.1 %), Claude 4 Sonnet(75.4 %), Perplexity Sonar Pro(74.4 %)를 포함한 주요 AI 모델을 능가하였습니다. 여러 신체 계통과 의학적 과제에 걸친 500개 문항으로 구성된 MedXpertQA 벤치마크에서 Vera는 62.2 %의 정확도를 달성하여, 전문화된 임상 추론 시나리오에서 강력한 성능을 입증하였습니다. Vera는 다섯 개 NEJM-AI 의학 전문 분야 중 네 개에서 가장 높은 정확도를 달성하였으며, 특히 소아과(93.9 %)와 내과(87.3 %)에서 두드러진 성능을 보였습니다. 다양한 평가 프레임워크에 걸친 이러한 결과는 Vera의 견고한 의학 지식 표현 및 추론 능력을 뒷받침하며, 임상 의사결정 지원을 위한 선도적 솔루션으로서의 위상을 확립합니다.
서론
다양한 임상 환경에 종사하는 의료 제공자는 최적의 환자 진료를 지원하기 위해 정확하고 근거 기반의 의학 지식에 신속하게 접근할 필요가 있습니다. 의학 문헌의 기하급수적 증가는 적시의 지식 검색 및 종합에 전례 없는 도전 과제를 제기합니다. Vera는 정교한 AI 에이전트와 첨단 검색 증강 생성(RAG) 기술을 결합하여 기존 방식보다 약 10배 빠르게 신뢰할 수 있는 임상 지침을 제공함으로써 이러한 중대한 요구에 대응합니다.
의료 AI 시스템의 평가는 실제 임상 시나리오에서의 견고한 성능을 보장하기 위해 다수의 영역에 걸친 엄정한 평가를 필요로 합니다. 개별 벤치마크가 가치 있는 통찰을 제공하기는 하지만, 다양한 지식 프레임워크 전반에 걸친 종합적 평가는 시스템의 역량과 한계에 대해 보다 완전한 그림을 제공합니다. 본 연구는 세 가지 상호 보완적인 평가 프레임워크, 즉 미국 의사면허시험(USMLE), 뉴잉글랜드 의학저널 AI 질의응답 데이터셋(NEJM-AI), 그리고 MedXpertQA 벤치마크를 사용하여 Vera에 대한 다중 벤치마크 평가를 제시합니다.
USMLE는 기초과학, 임상 지식, 환자 관리 영역 전반에 걸쳐 기초 의학 지식에 대한 표준화된 척도를 제공합니다. 그러나 이는 주로 면허 취득 이전의 교육 내용을 반영하며, 현대 임상 의사결정의 복잡성을 충분히 포착하지 못할 수 있습니다. 이러한 한계를 보완하기 위해, 우리는 다섯 개 주요 의학 전문 분야에 걸쳐 655개의 임상 지향 문항을 제시하는 NEJM-AI 벤치마크로 평가를 보완하여, 보다 실무와 관련된 시나리오에서의 성능에 대한 통찰을 제공합니다. 또한 우리는 다양한 신체 계통, 의학적 과제, 문항 유형에 걸친 임상 추론을 평가하는 500개 문항으로 구성된 MedXpertQA 벤치마크에서 Vera를 평가하여, 전문화된 임상 지식 영역에 대한 추가적인 통찰을 제공합니다.
이러한 서로 다른 평가 프레임워크 전반에 걸친 우리의 종합적 분석은 Vera의 강점과 성능 특성을 드러내며, 임상 의사결정 지원을 변혁하고, 의료 제공자의 효율성을 향상시키며, 궁극적으로 환자 진료의 질을 개선할 상당한 가능성을 입증합니다.
결과
다중 벤치마크 성능 개요
Vera는 세 가지 평가 프레임워크 전반에서 탁월한 성능을 입증하여, USMLE에서 97.5%, NEJM-AI 벤치마크에서 84.9%, MedXpertQA 벤치마크에서 62.2%를 달성하였습니다. 표 1은 모든 평가에 걸친 Vera의 성능을 요약합니다.
| 벤치마크 | 정확도 |
|---|---|
| USMLE(전체) | 97.5 % |
| Step 1 | 97.9 % |
| Step 2 CK | 98.2 % |
| Step 3 | 96.7 % |
| NEJM-AI(전체) | 84.9 % |
| MedXpertQA(전체) | 62.2 % |
USMLE 성능 분석
USMLE 평가에서 Vera는 모든 시험 단계에 걸쳐 거의 완벽에 가까운 정확도를 달성하여, 견고한 기초 의학 지식을 입증하였습니다. 단계 간의 최소한의 변동(범위: 96.7–98.2 %)은 Vera의 지식 표현이 기초과학 개념에서 환자 관리 의사결정을 요하는 복잡한 임상 시나리오에 이르기까지 효과적으로 확장됨을 시사합니다.
USMLE 경쟁 분석
Vera의 성능은 표준화된 의학 지식 평가에서 다른 의료 AI 시스템에 대한 명백한 우위를 확립합니다. 그림 1은 의료 AI 환경 전반에서 Vera의 경쟁 우위를 보여줍니다.
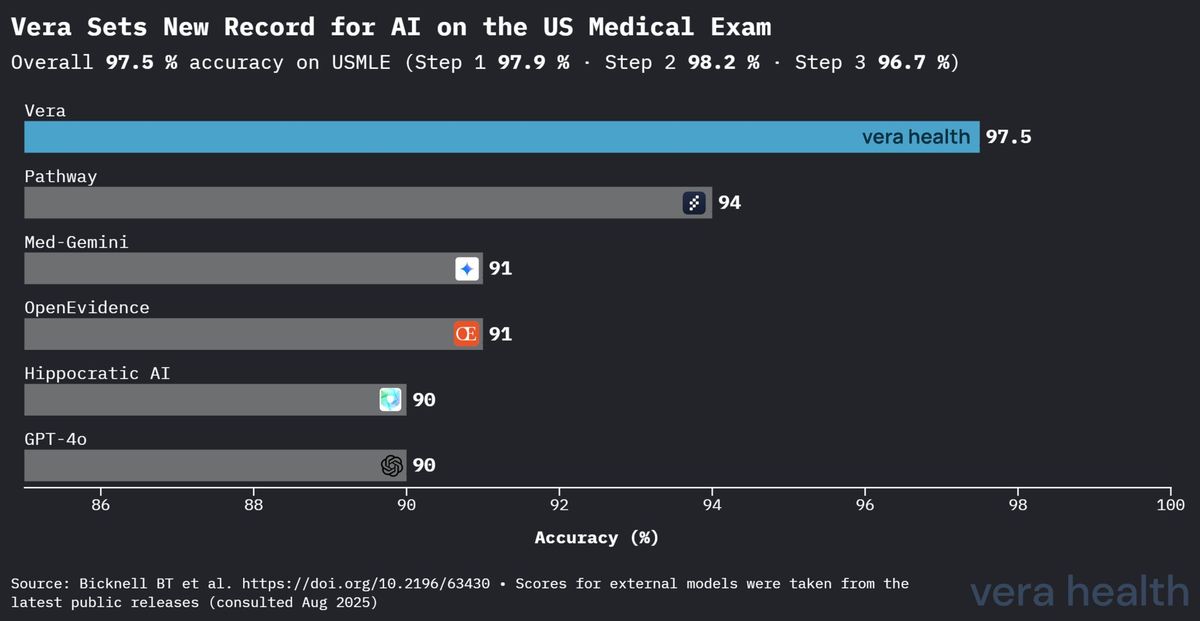
이 경쟁 분석은 몇 가지 핵심 통찰을 드러냅니다: (1) 두 번째로 우수한 성능을 보인 모델 대비 Vera의 3.5 퍼센트포인트 우위는 의학 지식 평가에서의 상당한 개선을 나타냅니다; (2) 범용 모델과 비교할 때 성능 격차가 현저히 확대되어 의료 특화 최적화의 가치를 부각합니다; 그리고 (3) Vera의 우위는 전문화된 의료 AI 시스템과 주요 범용 언어 모델 모두에 걸쳐 나타납니다.
NEJM-AI 경쟁 벤치마크 결과
NEJM-AI 벤치마크에서 Vera는 평가된 모든 모델 중 가장 높은 전체 정확도를 달성하여, 주요 AI 시스템을 상당한 차이로 능가하였습니다. 그림 2는 Vera의 경쟁적 우위를 보여줍니다.
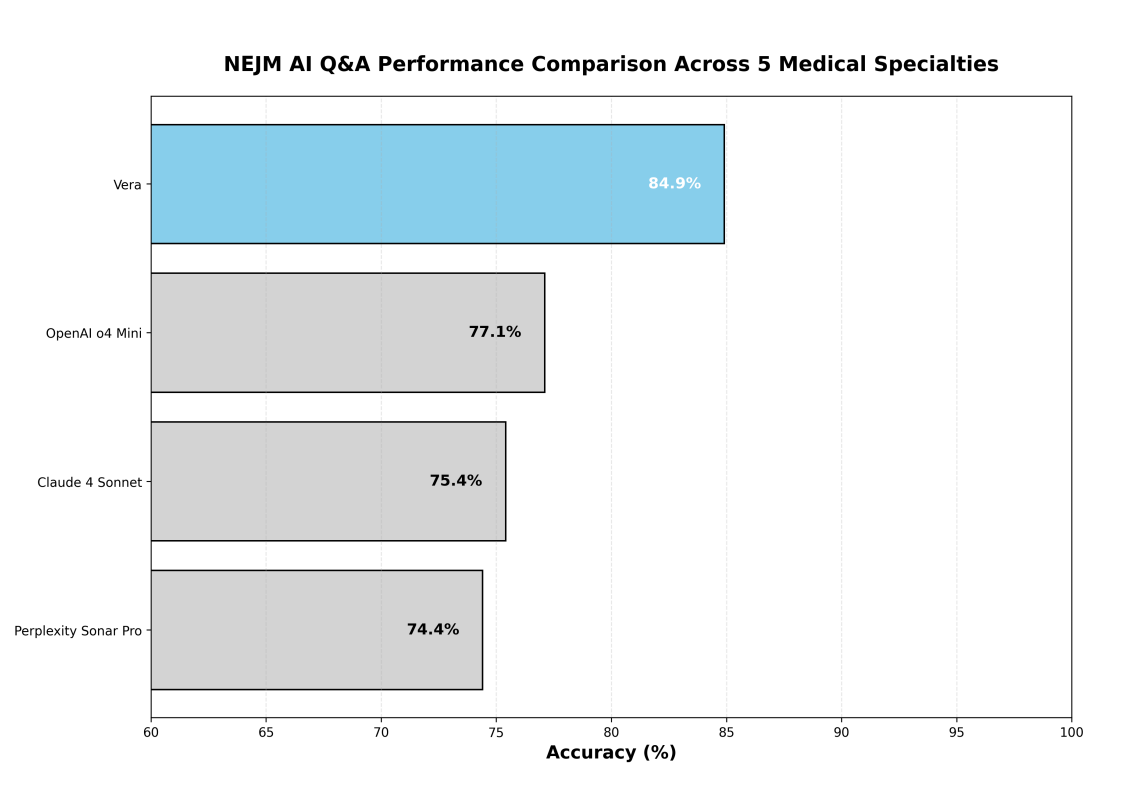
전문 분야별 성능 분석
Vera의 성능은 의학 전문 분야 전반에서 차이를 보였으나, 대부분의 영역에서 일관되게 강력한 결과를 나타냈습니다. 표 2는 전문 분야별 세부 정확도를 제시합니다.
| 의학 전문 분야 | 문항 수 | Vera 정확도 |
|---|---|---|
| 소아과 | 99 | 93.9 % |
| 정신과 | 150 | 88.7 % |
| 내과 | 126 | 87.3 % |
| 일반외과 | 141 | 83.0 % |
| 산부인과 | 139 | 74.1 % |
그림 3은 다섯 개 의학 전문 분야 전반에 걸쳐 경쟁 모델 대비 Vera의 성능을 상세히 비교하여 제시합니다.
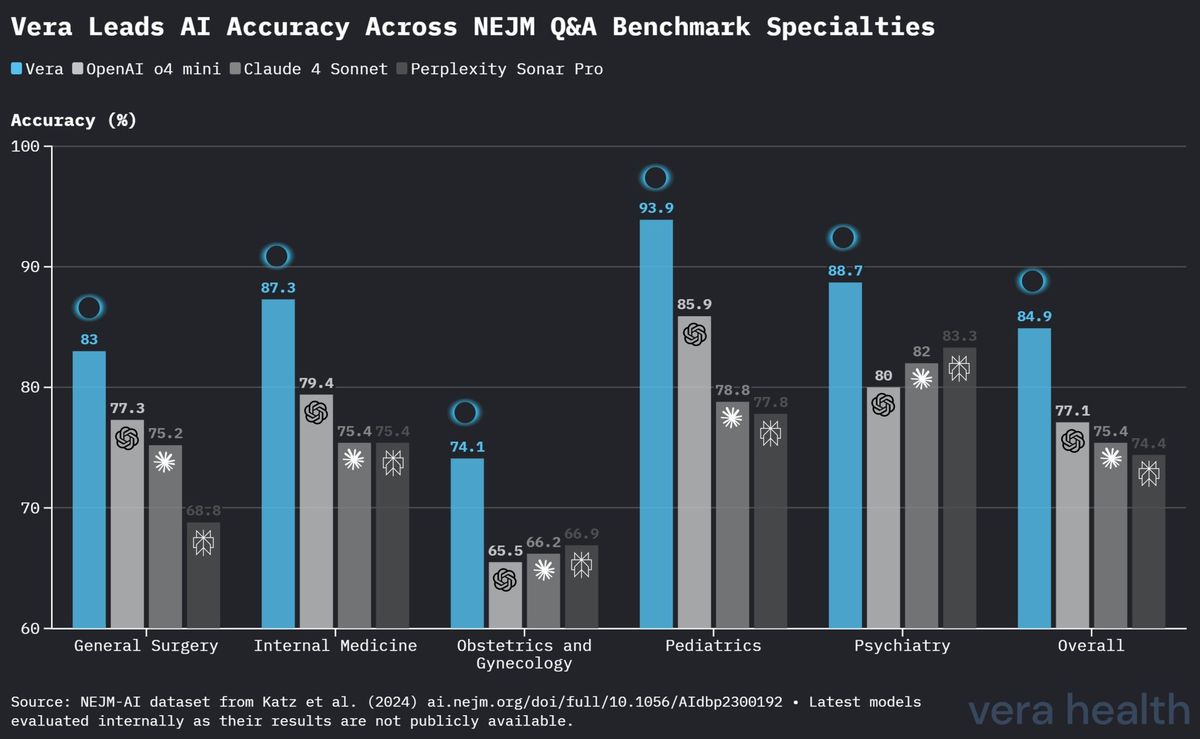
Vera는 다섯 개 전문 분야 중 네 개에서 가장 높은 정확도를 달성하였습니다: - 소아과: 93.9 % 정확도로 선도적인 성능 - 내과: 87.3 % 정확도로 강력한 성능 - 일반외과: 83.0 % 정확도로 경쟁 우위 - 산부인과: 74.1 % 정확도로 근소한 우위 - 정신과: 88.7 % 정확도로 강력한 성능
MedXpertQA 성능 분석
MedXpertQA 벤치마크에서 Vera는 500개의 다양한 의학 문항에 걸쳐 62.2 %의 정확도를 달성하여, 전문화된 임상 추론 시나리오에서 우수한 성능을 입증하였습니다. 표 3은 서로 다른 범주별 세부 성능 분석을 제시합니다.
| 범주 | 문항 수 | Vera 정확도 |
|---|---|---|
| 신체 계통별 | ||
| 외피계 | 16 | 81.2 % |
| 골격계 | 81 | 72.8 % |
| 근육계 | 36 | 72.2 % |
| 생식계 | 31 | 71.0 % |
| 소화계 | 60 | 63.3 % |
| 내분비계 | 37 | 62.2 % |
| 림프계 | 22 | 59.1 % |
| 신경계 | 72 | 56.9 % |
| 호흡계 | 32 | 56.2 % |
| 비뇨계 | 18 | 55.6 % |
| 심혈관계 | 68 | 51.5 % |
| 기타/해당 없음 | 27 | 48.1 % |
| 의학적 과제별 | ||
| 기초과학 | 139 | 66.9 % |
| 치료 | 157 | 61.8 % |
| 진단 | 204 | 59.3 % |
| 문항 유형별 | ||
| 이해 | 115 | 66.1 % |
| 추론 | 385 | 61.0 % |
MedXpertQA 결과는 Vera의 성능에서 몇 가지 주목할 만한 양상을 드러냅니다: - 신체 계통별 변동: 성능은 81.2 %(외피계)에서 48.1 %(기타/해당 없음)에 이르렀으며, 해부학적으로 구분되는 계통에서 가장 강력한 성능을 보였습니다 - 의학적 과제 성능: 기초과학 문항(66.9 %)이 임상 적용 문항을 능가하여, 기초 지식에서 더 강력한 성능을 시사합니다 - 문항 유형 분석: 이해 문항(66.1 %)이 추론 문항(61.0 %)에 비해 우수한 성능을 보여, 효과적인 지식 검색 능력을 나타냅니다
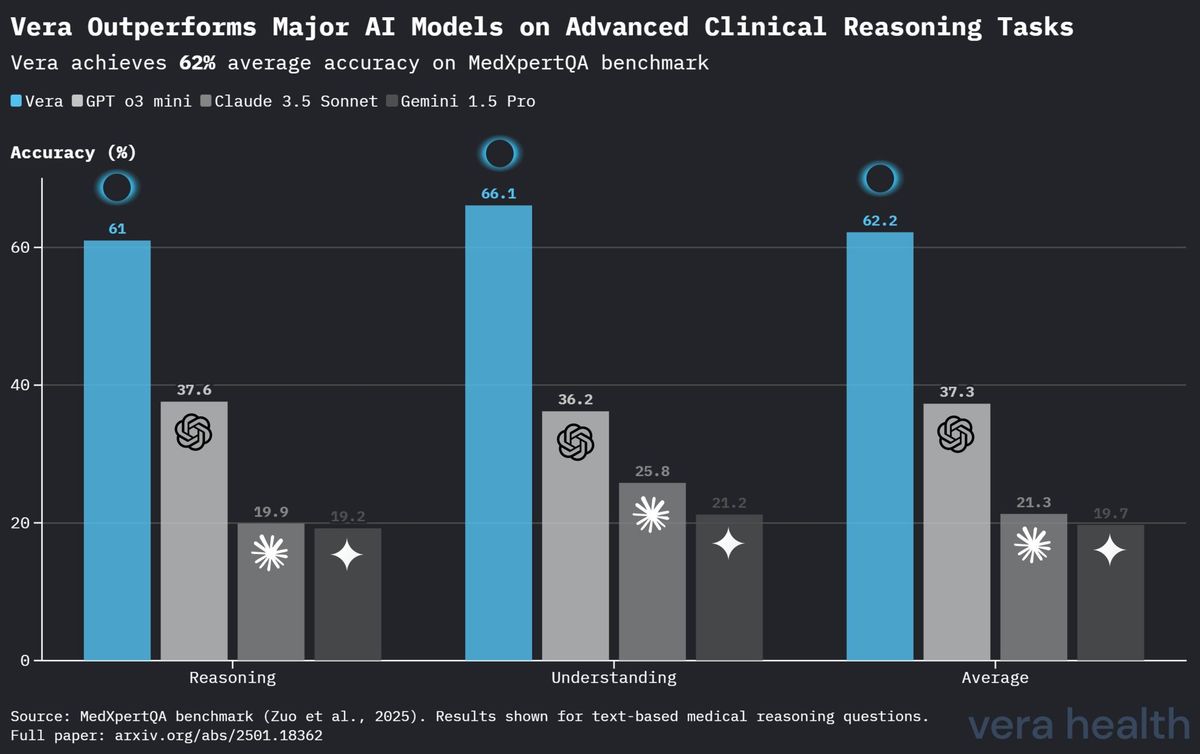
MedXpertQA에서의 모델 간 비교 성능
표 4는 MedXpertQA 벤치마크에서 다른 주요 AI 모델 대비 Vera의 성능에 대한 비교 분석을 제시하여, 전문화된 임상 추론 과제에서 Vera의 경쟁적 위상을 부각합니다.
| 모델 | 추론 | 이해 | 평균 |
|---|---|---|---|
| Vera | 61.0 % | 66.1 % | 62.2 % |
| OpenAI o3 Mini | 37.6 % | 36.2 % | 37.3 % |
| Claude 3.5 Sonnet | 19.9 % | 25.8 % | 21.3 % |
| Gemini 1.5 Pro | 19.2 % | 21.2 % | 19.7 % |
방법
평가 프레임워크
우리는 세 가지 서로 다른 의학 지식 평가 프레임워크, 즉 미국 의사면허시험(USMLE), 뉴잉글랜드 의학저널 AI 질의응답 데이터셋(NEJM-AI), 그리고 MedXpertQA 벤치마크를 사용하여 종합적인 다중 벤치마크 평가를 수행하였습니다. 이러한 3중 벤치마크 접근법은 기초 의학 지식, 현대 임상 추론 능력, 그리고 전문화된 임상 영역 전문성에 대한 평가를 가능하게 합니다.
USMLE 평가
우리는 세 가지 시험 단계 모두를 아우르는 공식 USMLE 준비 자료에서 객관식 문항을 표본 추출하였습니다: Step 1(기초과학), Step 2 Clinical Knowledge(임상 지식 및 술기), 그리고 Step 3(환자 관리). 각 문항은 임상 시나리오, 다수의 답안 선택지, 정답 키, 그리고 전문 분야 분류로 구성되었습니다. 문항은 벤치마크 특화 최적화 없이 운영 시스템 프롬프트를 사용하여 작성된 그대로 Vera에 제시되었습니다.
NEJM-AI 벤치마크 평가
NEJM-AI 데이터셋(Katz 등, 2024)은 다섯 개 주요 의학 전문 분야에 걸쳐 분포된 655개의 임상 지향 객관식 문항으로 구성됩니다: 일반외과(141문항), 내과(126문항), 산부인과(139문항), 소아과(99문항), 정신과(150문항). 이 벤치마크는 진료 중인 의사와 관련된 현대 임상 지식 및 추론 능력을 평가하도록 설계되었습니다. 원 연구는 이 벤치마크에서 GPT-4가 74.7%의 정확도를 달성하였다고 보고하였습니다.
MedXpertQA 벤치마크 평가
MedXpertQA 데이터셋(Zuo 등, 2025)은 전문가 수준의 의학 추론 및 이해를 평가하도록 설계된 고도로 도전적인 벤치마크입니다. 17개 의학 전문 분야와 11개 신체 계통에 걸친 4,460개 문항으로 구성된 MedXpertQA는 이용 가능한 의학 추론 평가 중 가장 종합적이고 난도가 높은 평가 중 하나입니다. 이 벤치마크는 두 개의 하위 집합을 포함합니다: 텍스트 기반 의학 평가를 위한 MedXpertQA Text와 멀티모달 의학 평가를 위한 MedXpertQA MM.
본 평가에서는 MedXpertQA Text 하위 집합에서 500개 문항의 대표 표본을 활용하여, 효율적인 평가를 가능하게 하면서도 벤치마크의 엄격한 기준을 유지하였습니다. 문항은 신체 계통(12개 범주), 의학적 과제(기초과학, 진단, 치료), 문항 유형(이해, 추론)별로 분류됩니다. 이 벤치마크는 기초과학에서 복잡한 임상 적용에 이르기까지 광범위한 의학 시나리오 전반에 걸쳐 전문화된 임상 지식 및 추론 능력을 평가하며, 이는 첨단 의료 AI 시스템을 평가하는 데 특히 가치가 있습니다.
실험 프로토콜
세 가지 벤치마크 모두에 대해 우리는 일관된 평가 프로토콜을 유지하였습니다: - 모든 문항은 벤치마크 특화 프롬프트 엔지니어링 없이 표준 운영 시스템 프롬프트를 사용하여 Vera에 제시되었습니다 - 선택적 Deep Dive 모드는 실제 환경에서 임상의가 선호하는 빠른 응답 모드를 반영하기 위해 비활성화되었습니다 - 각 문항은 사전 맥락이나 문항별 최적화 없이 독립적으로 처리되었습니다 - 응답 정확도는 제공된 정답과의 정확한 일치 여부로 결정되었습니다
경쟁 분석
NEJM-AI 벤치마크의 경우, 우리는 세 가지 주요 의료 AI 시스템, 즉 OpenAI o4 Mini, Claude 4 Sonnet, Perplexity Sonar Pro 대비 Vera의 성능을 비교하였습니다. OpenAI, Anthropic, Perplexity의 최신 모델은 공개적으로 이용 가능하지 않으므로, 우리는 자체 구현을 사용하여 내부 평가를 수행하였습니다. 모든 모델은 각각의 최적 구성을 사용하여 동일한 655문항 세트에서 평가되었습니다. 원 NEJM-AI 연구는 GPT-4가 74.7%의 정확도를 달성하였다고 보고하였으나, OpenAI o4 Mini가 우수한 성능을 보였으므로 우리는 이를 비교 분석에서 제외하였습니다.
통계 분석
우리는 전체 정확도, 전문 분야별 성능 지표, 그리고 비교 순위를 산출하였습니다. 전문 분야 전반에 걸친 성능 변동을 분석하여 영역별 강점과 개선이 필요한 부분을 식별하였습니다.
고찰
벤치마크의 상호 보완성과 임상적 함의
3중 벤치마크 평가는 Vera의 역량에 대해 서로 구별되면서도 상호 보완적인 통찰을 드러냅니다. 탁월한 USMLE 성능(97.5 % 정확도)은 기초과학, 임상 지식, 환자 관리 영역 전반에 걸친 기초 의학 지식의 숙달을 입증합니다. 주요 AI 모델 대비 경쟁적 우위를 보인 강력한 NEJM-AI 성능(84.9 % 정확도)은 현대 임상 추론 시나리오에서의 견고한 역량을 나타냅니다. MedXpertQA 성능(62.2 % 정확도)은 다양한 신체 계통과 의학적 과제에 걸친 전문화된 임상 영역 전문성 및 추론에 대한 통찰을 제공합니다.
벤치마크 간의 성능 차이(97.5 % 대 84.9 % 대 62.2 %)는 이러한 평가들의 서로 다른 성격과 복잡성을 반영할 가능성이 높습니다. USMLE 문항은 주로 확립된 정답 키를 가진 표준화된 의학 지식을 평가하는 반면, NEJM-AI 문항은 다수의 합리적 접근이 가능한 보다 미묘한 임상 시나리오를 제시합니다. MedXpertQA는 가장 도전적인 평가로서, 다수의 영역에 걸친 전문 지식의 통합을 요하는 복잡한 임상 추론 시나리오를 특징으로 하며, 이는 첨단 임상 역량에 대한 엄정한 시험이 됩니다.
경쟁적 위상
NEJM-AI 벤치마크에서의 Vera의 성능은 현재의 의료 AI 시스템에 대한 명백한 경쟁 우위를 확립합니다. 경쟁 모델 대비 상당한 우위는 고도로 경쟁적인 분야에서의 유의미한 개선을 나타냅니다. 더욱 중요한 점은, 다섯 개 의학 전문 분야 중 네 개에 걸친 Vera의 일관된 우위가 영역별 최적화가 아닌 광범위한 임상 지식을 입증한다는 것입니다.
전문 분야별 결과는 중요한 통찰을 드러냅니다: - 소아과: 93.9 %의 탁월한 정확도는 전문화된 발달 및 연령별 고려사항을 요하는 영역에서의 강력한 성능을 시사합니다 - 내과: 87.3 %의 정확도는 이 기초 전문 분야에 요구되는 광범위한 추론에서의 역량을 입증합니다 - 산부인과: 비교적 낮은 74.1 %의 정확도는 여전히 경쟁 모델을 앞서기는 하지만, 표적화된 개선의 여지가 있는 잠재적 영역을 시사합니다
시스템 일반화와 견고성
다양한 평가 프레임워크 전반에 걸친 일관되게 높은 성능은 Vera의 지식 표현 및 추론 메커니즘이 서로 다른 문항 형식, 난이도 수준, 임상 맥락에 걸쳐 효과적으로 일반화됨을 시사합니다. 이러한 견고성은 시스템이 다양한 질의 유형과 임상 시나리오를 처리해야 하는 임상 배치에 있어 특히 중요합니다.
한계 및 고려사항
이러한 고무적인 결과에도 불구하고, 몇 가지 한계는 고려할 가치가 있습니다: 1. 벤치마크 범위: 두 평가 모두 불확실성, 불완전한 정보, 다면적인 환자 양상을 흔히 수반하는 실제 임상 의사결정의 복잡성을 충분히 포착하지 못할 수 있는 객관식 형식에 의존합니다. 2. 임상 지식 대 학술 지식: 학술 벤치마크에서의 높은 성능이 최적의 실제 임상 효과성을 보장하지는 않습니다. Vera의 설계는 현대 임상 진료지침과 근거 기반 진료를 우선시하며, 이는 때때로 과거 시험 정답 키와 상이할 수 있습니다. 3. 전문 분야별 변동: 의학 전문 분야 전반에서 관찰된 성능 변동은 특정 영역, 특히 성능이 경쟁력이 있으면서도 가장 큰 개선 여지를 보인 산부인과가 표적화된 강화로부터 이익을 얻을 수 있음을 시사합니다. 4. 시간적 고려사항: 의학 지식은 새로운 연구 결과와 진료지침 갱신과 함께 빠르게 발전합니다. 시간이 지나도 성능을 유지하기 위해서는 지속적인 평가와 모델 갱신이 필수적입니다. 5. 평가 방법론: 두 벤치마크 모두 임상적으로 수용 가능한 응답의 전체 범위를 항상 반영하지는 못할 수 있는 사전 결정된 정답 키에 의존하며, 이는 모호한 시나리오에서 시스템 성능을 과소평가할 가능성이 있습니다.
결론
이 종합적인 다중 벤치마크 평가는 다양한 의학 지식 영역 전반에 걸친 Vera의 탁월한 역량을 입증합니다. 이 시스템은 USMLE(97.5 %)에서 거의 완벽에 가까운 정확도를 달성하였고, NEJM-AI 벤치마크(84.9 %)에서 경쟁적 우위를 확립하였으며, 도전적인 MedXpertQA 벤치마크(62.2 %)에서 우수한 성능을 입증하였습니다. NEJM-AI에서 Vera는 OpenAI o4 Mini, Claude 4 Sonnet, Perplexity Sonar Pro를 포함한 주요 AI 모델을 능가하였습니다.
주요 결과는 다음과 같습니다: - 광범위한 의학적 역량: 기초(USMLE), 현대 임상(NEJM-AI), 전문화된 추론(MedXpertQA) 지식 영역 전반에 걸친 일관되게 높은 성능 - 경쟁 우위: 일대일 평가에서 현재의 의료 AI 시스템에 대한 명백한 우위 - 전문 분야 견고성: 다섯 개 NEJM-AI 의학 전문 분야 중 네 개에서 선도적인 성능을 보였으며, 특히 소아과와 내과에서 두드러진 결과 - 영역별 전문성: MedXpertQA에서 다양한 신체 계통 전반에 걸친 강력한 성능을 보였으며, 특히 해부학적으로 구분되는 계통(외피계: 81.2 %, 골격계: 72.8 %)에서 두드러진 강점 - 지식 일반화: 다양한 문항 형식, 난이도 수준, 임상 맥락 전반에 걸친 효과적인 성능
이러한 결과는 Vera를 임상 의사결정 지원을 위한 선도적 솔루션으로 자리매김하게 하며, 의료 AI 시스템에 대한 현재의 벤치마크를 능가하는 역량을 입증합니다. 3중 벤치마크 접근법은 학술적, 임상 관련, 전문화된 추론 시나리오 전반에 걸친 시스템 성능에 대한 견고한 근거를 제공하며, 의학 교육, 임상 훈련, 진료 현장 의사결정 지원 응용 분야에의 배치를 뒷받침합니다.
데이터 이용 가능성
평가 데이터셋 및 상세 결과는 요청 시(enterprise@vera-health.ai) 이용 가능하며, 표준 데이터 이용 계약 및 개인정보 보호 안전장치에 따라 제공됩니다.
참고문헌
[1] Katz, U., Cohen, E., Shachar, E., Somer, J., Fink, A., Morse, E., Shreiber, B., & Wolf, I. (2024). GPT versus Resident Physicians — A Benchmark Based on Official Board Scores. NEJM AI, 1(5), AIdbp2300192. https://doi.org/10.1056/AIdbp2300192 [2] Zuo, Y., Qu, S., Li, Y., Chen, Z., Zhu, X., Hua, E., Zhang, K., Ding, N., & Zhou, B. (2025). MedXpertQA: Benchmarking expert-level medical reasoning and understanding. arXiv preprint arXiv:2501.18362. [3] Bicknell, B. T., Butler, D., Whalen, S., Ricks, J., Dixon, C. J., Clark, A. B., Spaedy, O., Skelton, A., Edupuganti, N., Dzubinski, L., Tate, H., Dyess, G., Lindeman, B., & Lehmann, L. S. (2024). ChatGPT-4 Omni Performance in USMLE Disciplines and Clinical Skills: Comparative Analysis. JMIR medical education, 10, e63430. https://doi.org/10.2196/63430
Vera Health 소개
Vera는 의료 제공자가 근거 기반 의사결정을 보다 효율적으로 내릴 수 있도록 지원하기 위해 설계된 AI 기반 임상 의사결정 지원(CDS) 도구입니다. Vera는 정교한 AI 에이전트와 검색 증강 생성(RAG) 기술을 활용하여 6,000만 건 이상의 동료 심사를 거친 의학 출판물로부터 지식을 종합함으로써, 진료 현장에서 신뢰할 수 있고 맥락에 적합한 답변을 제공합니다. 최첨단 AI 기술을 통해 Vera는 임상의가 환자 결과를 개선하고 의사결정 과정을 간소화할 수 있도록 지원합니다.


