
Avaliação Abrangente do Desempenho da Vera: Uma Análise Multibenchmark em Domínios do Conhecimento Médico
Resumo
Apresentamos uma avaliação abrangente da Vera, um sistema avançado de apoio à decisão clínica concebido para capacitar os profissionais de saúde com orientação médica instantânea e baseada em evidências. A Vera tira partido de sofisticados agentes de IA e de tecnologia de Geração Aumentada por Recuperação, sintetizando conhecimento de mais de 60 milhões de publicações médicas revistas por pares para fornecer respostas fiáveis e contextualmente adequadas. Esta análise multibenchmark avalia o desempenho da Vera em três domínios distintos do conhecimento médico: o United States Medical Licensing Examination (USMLE), o conjunto de dados de perguntas e respostas de IA do New England Journal of Medicine (NEJM-AI) e o benchmark MedXpertQA. No USMLE, a Vera alcançou uma exatidão global excecional de 97.5 %, com exatidões específicas por etapa de 97.9 % (Step 1), 98.2 % (Step 2 CK) e 96.7 % (Step 3). No benchmark NEJM-AI, composto por 655 perguntas em cinco especialidades médicas, a Vera demonstrou um desempenho superior com 84.9 % de exatidão, superando modelos de IA de referência, incluindo o OpenAI o4 Mini (77.1 %), o Claude 4 Sonnet (75.4 %) e o Perplexity Sonar Pro (74.4 %). No benchmark MedXpertQA, composto por 500 perguntas abrangendo múltiplos sistemas corporais e tarefas médicas, a Vera alcançou 62.2 % de exatidão, demonstrando um desempenho robusto em cenários especializados de raciocínio clínico. A Vera alcançou a exatidão mais elevada em quatro de cinco especialidades médicas do NEJM-AI, com um desempenho particularmente forte em Pediatria (93.9 %) e Medicina interna (87.3 %). Estes resultados em diversos quadros de avaliação sublinham a robusta representação do conhecimento médico e as capacidades de raciocínio da Vera, posicionando-a como uma solução de referência para o apoio à decisão clínica.
Introdução
Os profissionais de saúde em diversos ambientes clínicos necessitam de acesso rápido a conhecimento médico exato e baseado em evidências para apoiar um cuidado ideal dos doentes. O crescimento exponencial da literatura médica apresenta desafios sem precedentes para a recuperação e síntese atempadas do conhecimento. A Vera responde a esta necessidade crítica combinando sofisticados agentes de IA com tecnologia avançada de Geração Aumentada por Recuperação, fornecendo orientação clínica fiável aproximadamente dez vezes mais rápido do que os métodos convencionais.
A avaliação de sistemas de IA médica exige uma análise rigorosa em múltiplos domínios para garantir um desempenho robusto em cenários clínicos do mundo real. Embora os benchmarks individuais forneçam informações valiosas, uma avaliação abrangente em diversos quadros de conhecimento oferece uma imagem mais completa das capacidades e limitações do sistema. Este estudo apresenta uma avaliação multibenchmark da Vera utilizando três quadros de avaliação complementares: o United States Medical Licensing Examination (USMLE), o conjunto de dados de perguntas e respostas de IA do New England Journal of Medicine (NEJM-AI) e o benchmark MedXpertQA.
O USMLE fornece uma medida padronizada do conhecimento médico fundamental nos domínios das ciências básicas, do conhecimento clínico e da gestão de doentes. Contudo, reflete principalmente conteúdos educativos pré-licenciamento e pode não captar plenamente a complexidade da tomada de decisão clínica contemporânea. Para colmatar esta limitação, complementamos a nossa avaliação com o benchmark NEJM-AI, que apresenta 655 perguntas de orientação clínica em cinco grandes especialidades médicas, oferecendo informações sobre o desempenho em cenários mais relevantes para a prática. Adicionalmente, avaliamos a Vera no benchmark MedXpertQA, composto por 500 perguntas que avaliam o raciocínio clínico em diversos sistemas corporais, tarefas médicas e tipos de perguntas, fornecendo informações adicionais sobre domínios especializados do conhecimento clínico.
A nossa análise abrangente nestes quadros de avaliação distintos revela os pontos fortes e as características de desempenho da Vera, demonstrando um potencial substancial para transformar o apoio à decisão clínica, aumentar a eficiência dos profissionais e, em última análise, melhorar a qualidade do cuidado aos doentes.
Resultados
Panorama do Desempenho Multibenchmark
A Vera demonstrou um desempenho excecional nos três quadros de avaliação, alcançando 97.5% no USMLE, 84.9% no benchmark NEJM-AI e 62.2% no benchmark MedXpertQA. A Tabela 1 resume o desempenho da Vera em todas as avaliações.
| Benchmark | Exatidão |
|---|---|
| USMLE (Global) | 97.5 % |
| Step 1 | 97.9 % |
| Step 2 CK | 98.2 % |
| Step 3 | 96.7 % |
| NEJM-AI (Global) | 84.9 % |
| MedXpertQA (Global) | 62.2 % |
Análise do Desempenho no USMLE
Na avaliação USMLE, a Vera alcançou uma exatidão quase perfeita em todos os níveis do exame, demonstrando um robusto conhecimento médico fundamental. A variação mínima entre etapas (intervalo: 96.7–98.2 %) indica que a representação do conhecimento da Vera escala eficazmente desde conceitos de ciência básica até cenários clínicos complexos que exigem decisões de gestão de doentes.
Análise Competitiva no USMLE
O desempenho da Vera estabelece uma clara superioridade sobre outros sistemas de IA médica na avaliação padronizada do conhecimento médico. A Figura 1 demonstra a vantagem competitiva da Vera no panorama da IA médica.
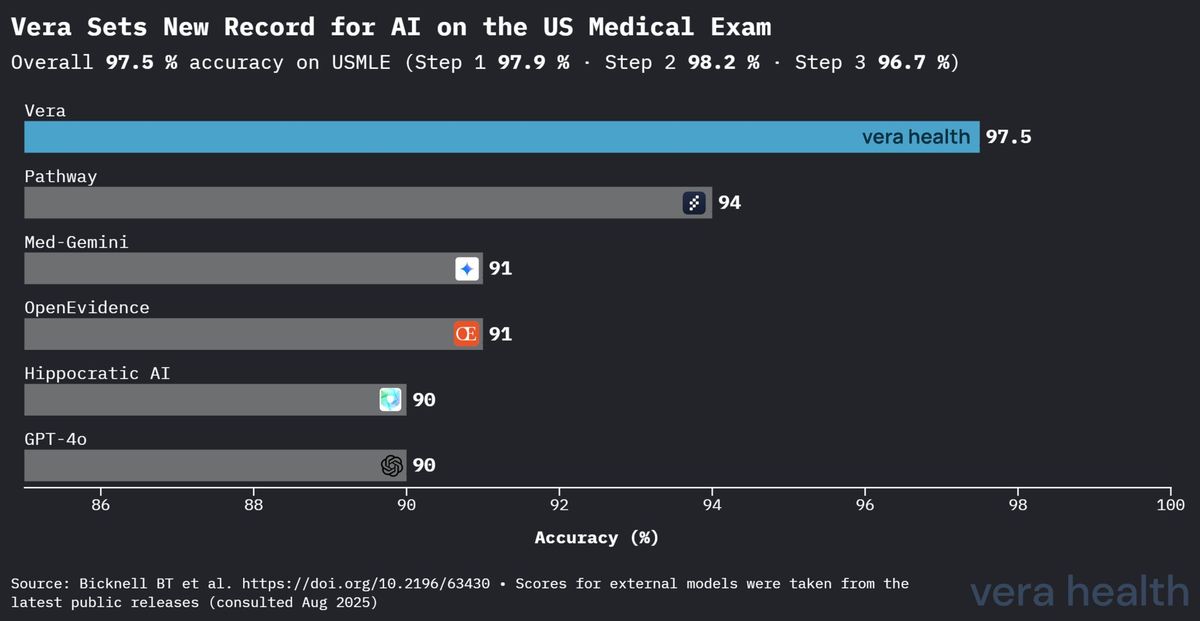
Esta análise competitiva revela várias conclusões fundamentais: (1) a vantagem de 3,5 pontos percentuais da Vera sobre o segundo modelo com melhor desempenho representa uma melhoria substancial na avaliação do conhecimento médico; (2) a diferença de desempenho aumenta significativamente em comparação com os modelos de uso geral, realçando o valor da otimização específica para a área médica; e (3) a superioridade da Vera abrange tanto sistemas especializados de IA médica como os principais modelos de linguagem de uso geral.
Resultados do Benchmark Competitivo NEJM-AI
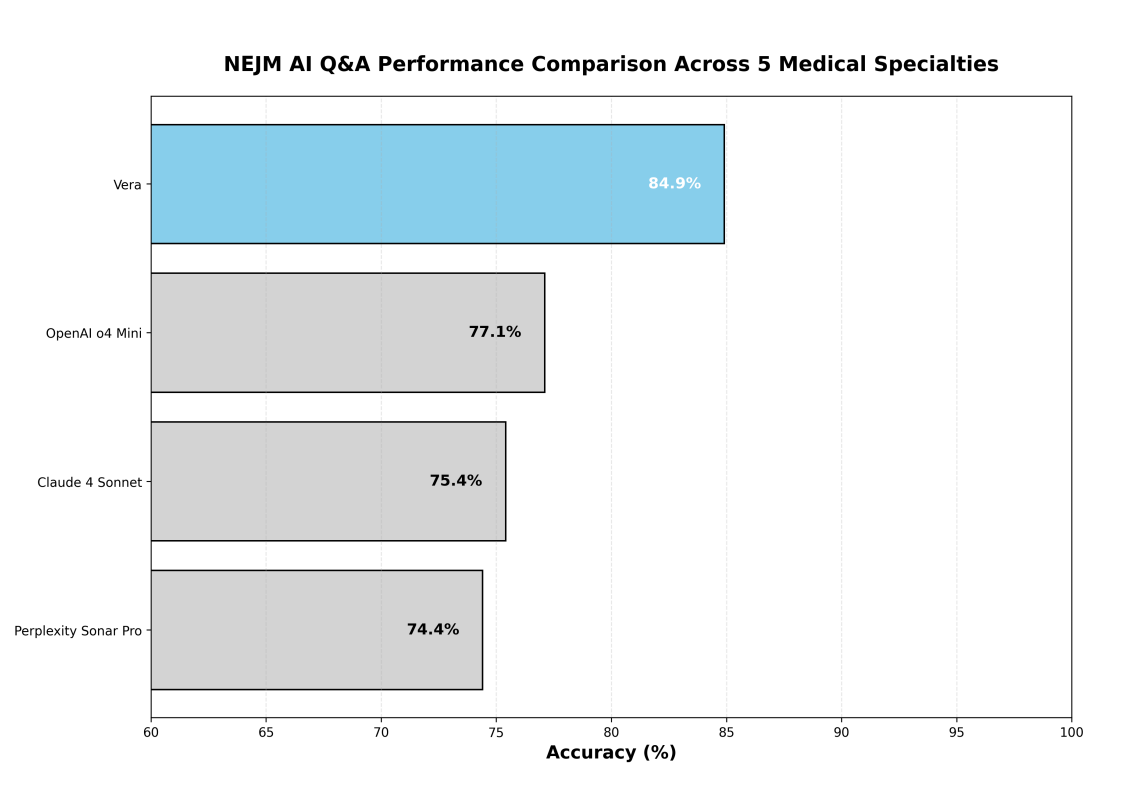
No benchmark NEJM-AI, a Vera alcançou a exatidão global mais elevada entre todos os modelos avaliados, superando os principais sistemas de IA por margens substanciais. A Figura 2 demonstra a superioridade competitiva da Vera.
Análise do Desempenho Específico por Especialidade
O desempenho da Vera variou consoante as especialidades médicas, com resultados consistentemente fortes na maioria dos domínios. A Tabela 2 apresenta exatidões detalhadas específicas por especialidade.
| Especialidade Médica | Perguntas | Exatidão da Vera |
|---|---|---|
| Pediatria | 99 | 93.9 % |
| Psiquiatria | 150 | 88.7 % |
| Medicina interna | 126 | 87.3 % |
| Cirurgia geral | 141 | 83.0 % |
| Ginecologia e obstetrícia | 139 | 74.1 % |
A Figura 3 fornece uma comparação detalhada do desempenho da Vera face aos modelos concorrentes nas cinco especialidades médicas.
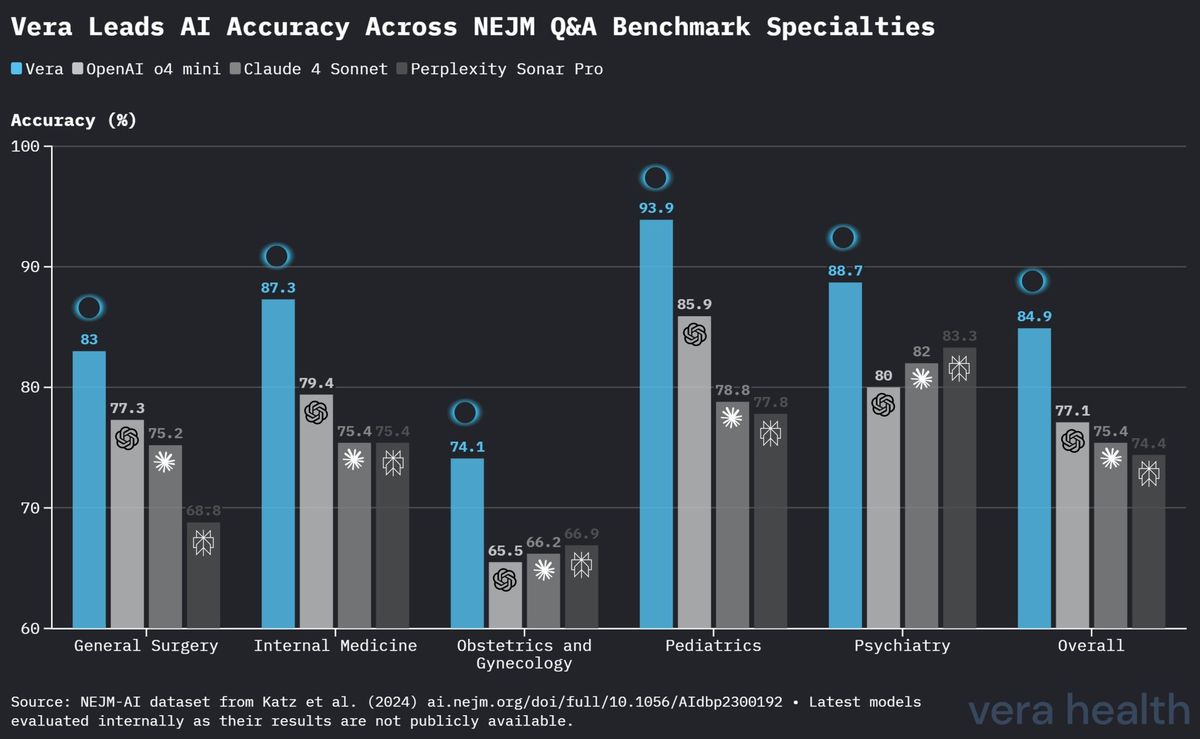
A Vera alcançou a exatidão mais elevada em quatro de cinco especialidades: - Pediatria: Desempenho líder com 93.9 % de exatidão - Medicina interna: Desempenho forte com 87.3 % de exatidão - Cirurgia geral: Vantagem competitiva com 83.0 % de exatidão - Ginecologia e obstetrícia: Liderança modesta com 74.1 % de exatidão - Psiquiatria: Desempenho forte com 88.7 % de exatidão
Análise do Desempenho no MedXpertQA
No benchmark MedXpertQA, a Vera alcançou 62.2 % de exatidão em 500 perguntas médicas diversas, demonstrando um desempenho competente em cenários especializados de raciocínio clínico. A Tabela 3 apresenta repartições detalhadas do desempenho nas diferentes categorias.
| Categoria | Perguntas | Exatidão da Vera |
|---|---|---|
| Por Sistema Corporal | ||
| Tegumentar | 16 | 81.2 % |
| Esquelético | 81 | 72.8 % |
| Muscular | 36 | 72.2 % |
| Reprodutor | 31 | 71.0 % |
| Digestivo | 60 | 63.3 % |
| Endócrino | 37 | 62.2 % |
| Linfático | 22 | 59.1 % |
| Nervoso | 72 | 56.9 % |
| Respiratório | 32 | 56.2 % |
| Urinário | 18 | 55.6 % |
| Cardiovascular | 68 | 51.5 % |
| Outro/N.D. | 27 | 48.1 % |
| Por Tarefa Médica | ||
| Ciência Básica | 139 | 66.9 % |
| Tratamento | 157 | 61.8 % |
| Diagnóstico | 204 | 59.3 % |
| Por Tipo de Pergunta | ||
| Compreensão | 115 | 66.1 % |
| Raciocínio | 385 | 61.0 % |
Os resultados do MedXpertQA revelam vários padrões notáveis no desempenho da Vera: - Variação por Sistema Corporal: O desempenho variou entre 81.2 % (Tegumentar) e 48.1 % (Outro/N.D.), com o desempenho mais forte em sistemas anatomicamente discretos - Desempenho por Tarefa Médica: As perguntas de Ciência Básica (66.9 %) superaram as aplicações clínicas, sugerindo um desempenho mais forte no conhecimento fundamental - Análise por Tipo de Pergunta: As perguntas de Compreensão (66.1 %) apresentaram um desempenho superior em comparação com as perguntas de Raciocínio (61.0 %), indicando capacidades eficazes de recuperação de conhecimento
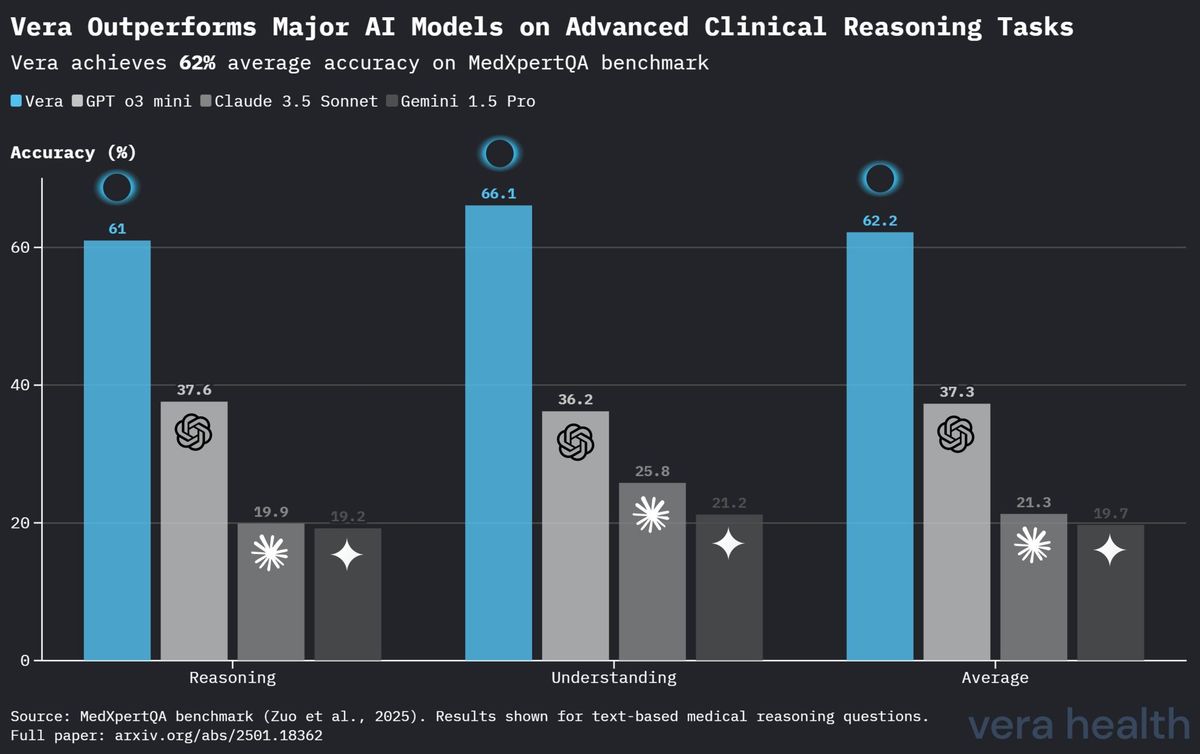
Desempenho Comparativo dos Modelos no MedXpertQA
A Tabela 4 apresenta uma análise comparativa do desempenho da Vera face a outros modelos de IA de referência no benchmark MedXpertQA, realçando o posicionamento competitivo da Vera em tarefas especializadas de raciocínio clínico.
| Modelo | Raciocínio | Compreensão | Média |
|---|---|---|---|
| Vera | 61.0 % | 66.1 % | 62.2 % |
| OpenAI o3 Mini | 37.6 % | 36.2 % | 37.3 % |
| Claude 3.5 Sonnet | 19.9 % | 25.8 % | 21.3 % |
| Gemini 1.5 Pro | 19.2 % | 21.2 % | 19.7 % |
Métodos
Quadro de Avaliação
Realizámos uma avaliação multibenchmark abrangente utilizando três quadros distintos de avaliação do conhecimento médico: o United States Medical Licensing Examination (USMLE), o conjunto de dados de perguntas e respostas de IA do New England Journal of Medicine (NEJM-AI) e o benchmark MedXpertQA. Esta abordagem de três benchmarks permite avaliar o conhecimento médico fundamental, as capacidades contemporâneas de raciocínio clínico e a perícia em domínios clínicos especializados.
Avaliação USMLE
Selecionámos perguntas de escolha múltipla de recursos oficiais de preparação para o USMLE, abrangendo as três etapas do exame: Step 1 (ciência básica), Step 2 Clinical Knowledge (conhecimento e competências clínicas) e Step 3 (gestão de doentes). Cada pergunta incluía uma vinheta clínica, várias opções de resposta, uma chave de resposta de referência e uma classificação por especialidade. As perguntas foram apresentadas à Vera exatamente como redigidas, utilizando o prompt de sistema de produção sem otimização específica para o benchmark.
Avaliação do Benchmark NEJM-AI
O conjunto de dados NEJM-AI (Katz et al., 2024) é constituído por 655 perguntas de escolha múltipla de orientação clínica distribuídas por cinco grandes especialidades médicas: Cirurgia geral (141 perguntas), Medicina interna (126 perguntas), Ginecologia e obstetrícia (139 perguntas), Pediatria (99 perguntas) e Psiquiatria (150 perguntas). Este benchmark foi concebido para avaliar o conhecimento e as capacidades de raciocínio clínico contemporâneos relevantes para os médicos em exercício. O estudo original relatou que o GPT-4 alcançou 74.7% de exatidão neste benchmark.
Avaliação do Benchmark MedXpertQA
O conjunto de dados MedXpertQA (Zuo et al., 2025) é um benchmark altamente exigente, concebido para avaliar o raciocínio e a compreensão médicos de nível especializado. Composto por 4.460 perguntas que abrangem 17 especialidades médicas e 11 sistemas corporais, o MedXpertQA representa uma das avaliações de raciocínio médico mais abrangentes e difíceis disponíveis. O benchmark inclui dois subconjuntos: MedXpertQA Text para avaliação médica baseada em texto e MedXpertQA MM para avaliação médica multimodal.
Para a nossa avaliação, utilizámos uma amostra representativa de 500 perguntas do subconjunto MedXpertQA Text, mantendo os rigorosos padrões do benchmark e permitindo simultaneamente uma avaliação eficiente. As perguntas estão categorizadas por sistema corporal (12 categorias), tarefa médica (Ciência Básica, Diagnóstico, Tratamento) e tipo de pergunta (Compreensão, Raciocínio). Este benchmark avalia o conhecimento clínico especializado e as capacidades de raciocínio num amplo espetro de cenários médicos, desde a ciência fundamental até às aplicações clínicas complexas, tornando-o particularmente valioso para a avaliação de sistemas avançados de IA médica.
Protocolo Experimental
Para os três benchmarks, mantivemos protocolos de avaliação consistentes: - Todas as perguntas foram apresentadas à Vera utilizando o prompt de sistema de produção padrão, sem qualquer engenharia de prompt específica para o benchmark - O modo opcional Deep Dive foi desativado para refletir o modo de resposta rápida preferido pelos clínicos em contextos do mundo real - Cada pergunta foi processada de forma independente, sem contexto prévio ou otimização específica por pergunta - A exatidão das respostas foi determinada por correspondência exata com as respostas de referência fornecidas
Análise Competitiva
Para o benchmark NEJM-AI, comparámos o desempenho da Vera com três sistemas de IA médica de referência: OpenAI o4 Mini, Claude 4 Sonnet e Perplexity Sonar Pro. Uma vez que os modelos mais recentes da OpenAI, da Anthropic e da Perplexity não estão disponíveis publicamente, realizámos avaliações internas utilizando as nossas próprias implementações. Todos os modelos foram avaliados no mesmo conjunto de 655 perguntas, utilizando as respetivas configurações ótimas. Embora o estudo original do NEJM-AI tenha relatado que o GPT-4 alcançou 74.7% de exatidão, excluímo-lo da nossa análise comparativa, dado que o OpenAI o4 Mini demonstrou um desempenho superior.
Análise Estatística
Calculámos as taxas de exatidão global, as métricas de desempenho específicas por especialidade e as classificações comparativas. As variações de desempenho entre especialidades foram analisadas para identificar pontos fortes específicos de cada domínio e áreas a melhorar.
Discussão
Complementaridade dos Benchmarks e Implicações Clínicas
A avaliação de três benchmarks revela informações distintas mas complementares sobre as capacidades da Vera. O desempenho excecional no USMLE (97.5 % de exatidão) demonstra o domínio do conhecimento médico fundamental nos domínios da ciência básica, do conhecimento clínico e da gestão de doentes. O forte desempenho no NEJM-AI (84.9 % de exatidão), com superioridade competitiva sobre os principais modelos de IA, indica capacidades robustas em cenários contemporâneos de raciocínio clínico. O desempenho no MedXpertQA (62.2 % de exatidão) fornece informações sobre a perícia em domínios clínicos especializados e o raciocínio em diversos sistemas corporais e tarefas médicas.
O diferencial de desempenho entre os benchmarks (97.5 % vs 84.9 % vs 62.2 %) reflete provavelmente a natureza e a complexidade distintas destas avaliações. As perguntas do USMLE avaliam principalmente o conhecimento médico padronizado com chaves de resposta estabelecidas, enquanto as perguntas do NEJM-AI apresentam cenários clínicos mais matizados que podem admitir múltiplas abordagens razoáveis. O MedXpertQA representa a avaliação mais exigente, apresentando cenários complexos de raciocínio clínico que exigem a integração de conhecimento especializado em múltiplos domínios, tornando-o um teste rigoroso de competência clínica avançada.
Posicionamento Competitivo
O desempenho da Vera no benchmark NEJM-AI estabelece claras vantagens competitivas sobre os atuais sistemas de IA médica. A vantagem substancial sobre os modelos concorrentes representa uma melhoria significativa num campo altamente competitivo. Mais significativamente, a superioridade consistente da Vera em quatro de cinco especialidades médicas demonstra um conhecimento clínico de base ampla, em vez de uma otimização específica de domínio.
Os resultados específicos por especialidade revelam informações importantes: - Pediatria: A excecional exatidão de 93.9 % sugere um desempenho forte num domínio que exige considerações especializadas de desenvolvimento e específicas da idade - Medicina interna: A exatidão de 87.3 % demonstra competência no raciocínio de base ampla exigido por esta especialidade fundamental - Ginecologia e obstetrícia: A exatidão comparativamente mais baixa de 74.1 %, embora ainda lidere os concorrentes, indica potenciais áreas para melhoria direcionada
Generalização e Robustez do Sistema
O desempenho consistentemente elevado em diversos quadros de avaliação sugere que os mecanismos de representação do conhecimento e de raciocínio da Vera generalizam eficazmente em diferentes formatos de perguntas, níveis de dificuldade e contextos clínicos. Esta robustez é particularmente importante para a implementação clínica, onde o sistema tem de lidar com diversos tipos de consultas e cenários clínicos.
Limitações e Considerações
Apesar destes resultados encorajadores, várias limitações merecem consideração: 1. Âmbito do Benchmark: Ambas as avaliações assentam em formatos de escolha múltipla que podem não captar plenamente a complexidade da tomada de decisão clínica do mundo real, que frequentemente envolve incerteza, informação incompleta e apresentações multifacetadas dos doentes. 2. Conhecimento Clínico vs Académico: Um desempenho elevado em benchmarks académicos não garante uma eficácia clínica ótima no mundo real. A conceção da Vera prioriza as diretrizes clínicas contemporâneas e a prática baseada em evidências, que podem ocasionalmente divergir das chaves de resposta históricas dos exames. 3. Variação por Especialidade: A variação de desempenho observada entre as especialidades médicas sugere que certos domínios podem beneficiar de uma melhoria direcionada, particularmente a Ginecologia e obstetrícia, onde o desempenho, embora competitivo, apresentou a maior margem de melhoria. 4. Considerações Temporais: O conhecimento médico evolui rapidamente com novos resultados de investigação e atualizações de diretrizes. A avaliação contínua e a atualização do modelo serão essenciais para manter o desempenho ao longo do tempo. 5. Metodologia de Avaliação: Ambos os benchmarks assentam em chaves de resposta predeterminadas que podem nem sempre refletir o espetro completo de respostas clinicamente aceitáveis, podendo subestimar o desempenho do sistema em cenários ambíguos.
Conclusões
Esta avaliação multibenchmark abrangente demonstra as capacidades excecionais da Vera em diversos domínios do conhecimento médico. O sistema alcançou uma exatidão quase perfeita no USMLE (97.5 %), estabeleceu uma superioridade competitiva no benchmark NEJM-AI (84.9 %) e demonstrou um desempenho competente no exigente benchmark MedXpertQA (62.2 %). No NEJM-AI, a Vera superou modelos de IA de referência, incluindo o OpenAI o4 Mini, o Claude 4 Sonnet e o Perplexity Sonar Pro.
As principais conclusões incluem: - Competência Médica Ampla: Desempenho consistentemente elevado em domínios de conhecimento fundamental (USMLE), clínico contemporâneo (NEJM-AI) e de raciocínio especializado (MedXpertQA) - Vantagem Competitiva: Clara superioridade sobre os atuais sistemas de IA médica em avaliação direta - Robustez por Especialidade: Desempenho líder em quatro de cinco especialidades médicas do NEJM-AI, com resultados particularmente fortes em Pediatria e Medicina interna - Perícia Específica de Domínio: Desempenho forte em diversos sistemas corporais no MedXpertQA, com particular força em sistemas anatomicamente discretos (Tegumentar: 81.2 %, Esquelético: 72.8 %) - Generalização do Conhecimento: Desempenho eficaz em diversos formatos de perguntas, níveis de dificuldade e contextos clínicos
Estes resultados posicionam a Vera como uma solução de referência para o apoio à decisão clínica, com capacidades demonstradas que excedem os benchmarks atuais para sistemas de IA médica. A abordagem de três benchmarks fornece evidências robustas do desempenho do sistema em cenários académicos, clinicamente relevantes e de raciocínio especializado, apoiando a implementação em educação médica, formação clínica e aplicações de apoio à decisão no ponto de cuidados.
Disponibilidade dos Dados
Os conjuntos de dados de avaliação e os resultados detalhados estão disponíveis mediante pedido (enterprise@vera-health.ai) e serão fornecidos sujeitos a acordos padrão de utilização de dados e a salvaguardas de privacidade.
Referências
[1] Katz, U., Cohen, E., Shachar, E., Somer, J., Fink, A., Morse, E., Shreiber, B., & Wolf, I. (2024). GPT versus Resident Physicians — A Benchmark Based on Official Board Scores. NEJM AI, 1(5), AIdbp2300192. https://doi.org/10.1056/AIdbp2300192 [2] Zuo, Y., Qu, S., Li, Y., Chen, Z., Zhu, X., Hua, E., Zhang, K., Ding, N., & Zhou, B. (2025). MedXpertQA: Benchmarking expert-level medical reasoning and understanding. arXiv preprint arXiv:2501.18362. [3] Bicknell, B. T., Butler, D., Whalen, S., Ricks, J., Dixon, C. J., Clark, A. B., Spaedy, O., Skelton, A., Edupuganti, N., Dzubinski, L., Tate, H., Dyess, G., Lindeman, B., & Lehmann, L. S. (2024). ChatGPT-4 Omni Performance in USMLE Disciplines and Clinical Skills: Comparative Analysis. JMIR medical education, 10, e63430. https://doi.org/10.2196/63430
Sobre a Vera Health
A Vera é uma ferramenta de Apoio à Decisão Clínica (CDS) baseada em IA, concebida para auxiliar os profissionais de saúde a tomar decisões baseadas em evidências de forma mais eficiente. A Vera tira partido de sofisticados agentes de IA e de tecnologia de Geração Aumentada por Recuperação, sintetizando conhecimento de mais de 60 milhões de publicações médicas revistas por pares para fornecer respostas fiáveis e contextualmente adequadas no ponto de cuidados. Com a sua tecnologia de IA de vanguarda, a Vera capacita os clínicos a melhorar os resultados dos doentes e a otimizar os processos de tomada de decisão.


